由于训练大模型非常耗时,再加上训练语料本身比较滞后,所以大模型存在知识限制问题:
- 知识数据比较落后,往往是几个月前的
- 不包含太过专业领域或者企业私有的数据
为了解决这些问题,我们就需要用到RAG了。
1.RAG原理
要解决大模型知识限制问题就是给大模型外挂一个知识库,可以是专业领域知识,也可以是企业私有数据。
不过知识库不能简单地拼接在提示词中。
因为通常知识库数据量都是非常大的,而大模型上下文大是有大小限制的,因此知识库不能直接写在提示词中。
我们需要想办法从庞大的知识库中找到与用户问题相关的一小部分,组装成提示词,发送给大模型就可以。
从知识库找到用户问题相关内容就需要用到向量模型的知识。
1.1.向量模型
向量是空间中有方向和长度的量,空间可以是二维,三维与多维。
向量既然是在空间中,两个向量之间就一定能计算距离。
以二维向量为例,向量之间距离的两种计算方法:
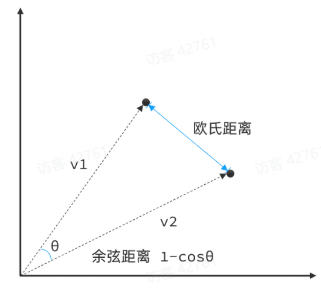
通常,两个向量之间欧式距离越近,我们认为两个向量的相似度越高(距离值越小,相似度越高)
所以,如果我们能把文本转为向量,就可以通过向量距离来判断文本的相似度了。
现在有不少专门的向量模型,可以实现将文本向量化。一个好的向量模型,就是要尽可能让文本含义相似的向量,在空间中距离更近。
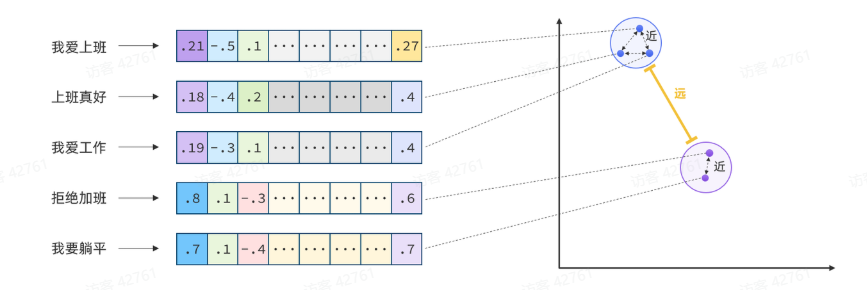
接下来准备一个向量模型,用于将文本向量化。
阿里云百炼平台就提供了这样的模型:
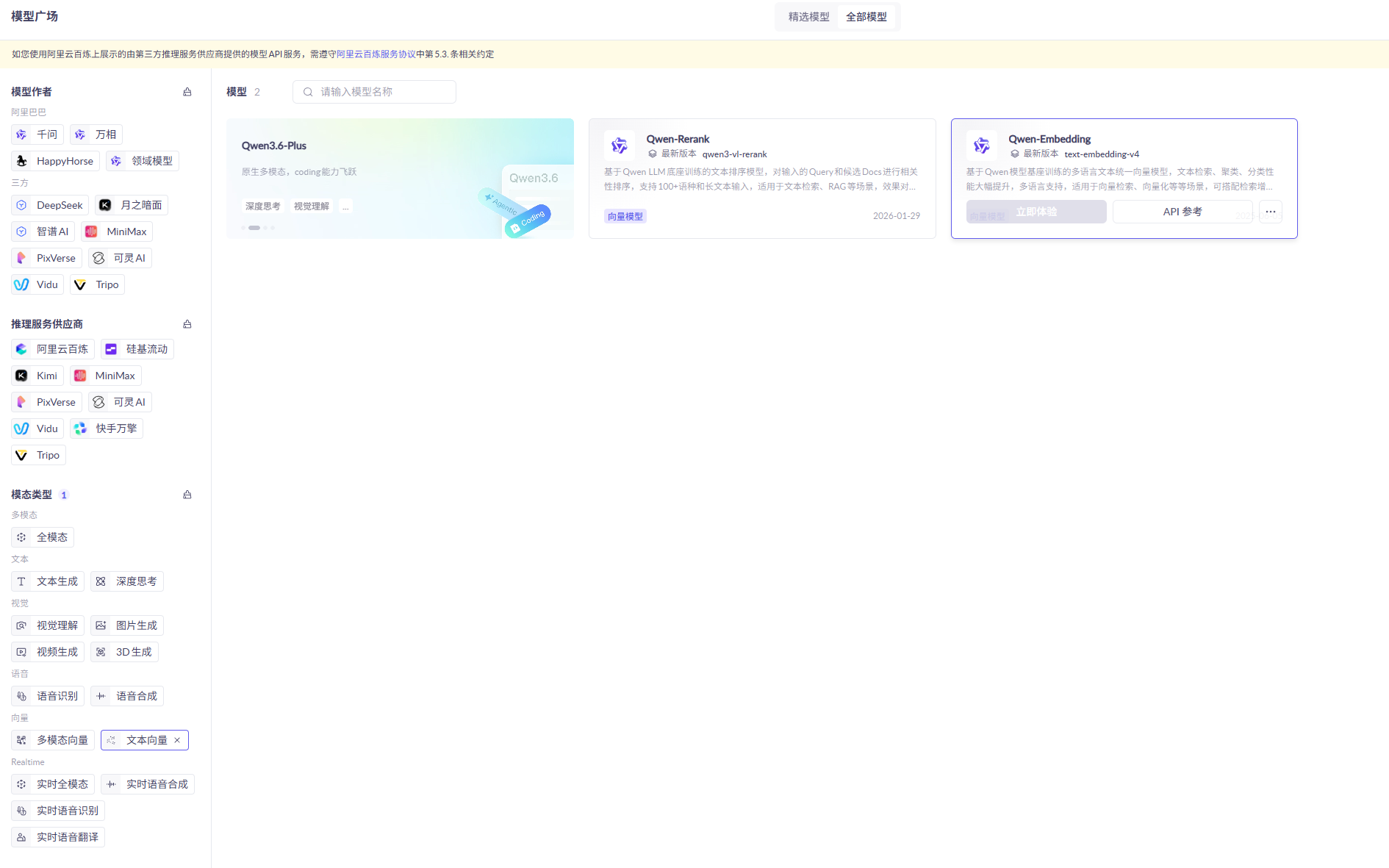
选择Qwen-Embedding,这个模型兼容OpenAI,所以我们采用OpenAI的配置,但地址和API_KEY都采用阿里云百炼平台的地址。
修改application.yaml,添加向量模型配置:
spring:
application:
name: spring-ai
ai:
open-ai:
base-url: https://dashscope.aliyuncs.com/compatible-mode
api-key: ${OPENAI_API_KEY}
chat:
options:
model: qwen-max-latest
embedding:
options:
model: text-embedding-v4
dimensions: 10241.2.向量模型测试
文本向量化以后,可以通过向量之间的距离来判断文本相似度。
首先在项目中写一个工具类,用来计算向量之间的欧式距离和余弦距离。
新建VectorDistanceUtils类
package com.example.ai.util;
public class VectorDistanceUtils {
//防止实例化
private VectorDistanceUtils() {}
//浮点数计算精度阈值
private static final double EPSILON=1e-12;
/**
* 计算欧氏距离
* @param vectorA 向量A(非空且与B等长)
* @param vectorB 向量B(非空且与A等长)
* @return 欧氏距离
* @throws IllegalArgumentException 参数不合法时抛出
*/
public static double euclideanDistance(float[] vectorA, float[] vectorB) {
validateVectors(vectorA, vectorB);
double sum = 0.0;
for (int i = 0; i < vectorA.length; i++) {
double diff = vectorA[i] - vectorB[i];
sum += diff * diff;
}
return Math.sqrt(sum);
}
/**
* 计算余弦距离
* @param vectorA 向量A(非空且与B等长)
* @param vectorB 向量B(非空且与A等长)
* @return 余弦距离,范围[0, 2]
* @throws IllegalArgumentException 参数不合法或零向量时抛出
*/
public static double cosineDistance(float[] vectorA, float[] vectorB) {
validateVectors(vectorA, vectorB);
double dotProduct = 0.0;
double normA = 0.0;
double normB = 0.0;
for (int i = 0; i < vectorA.length; i++) {
dotProduct += vectorA[i] * vectorB[i];
normA += vectorA[i] * vectorA[i];
normB += vectorB[i] * vectorB[i];
}
normA = Math.sqrt(normA);
normB = Math.sqrt(normB);
// 处理零向量情况
if (normA < EPSILON || normB < EPSILON) {
throw new IllegalArgumentException("Vectors cannot be zero vectors");
}
// 处理浮点误差,确保结果在[-1,1]范围内
double similarity = dotProduct / (normA * normB);
similarity = Math.max(Math.min(similarity, 1.0), -1.0);
return 1 - similarity;
}
// 参数校验统一方法
private static void validateVectors(float[] a, float[] b) {
if (a == null || b == null) {
throw new IllegalArgumentException("Vectors cannot be null");
}
if (a.length != b.length) {
throw new IllegalArgumentException("Vectors must have same dimension");
}
if (a.length == 0) {
throw new IllegalArgumentException("Vectors cannot be empty");
}
}
}接下来写测试类:
@SpringBootTest
class SpringAiApplicationTests {
//自动注入向量模型
@Autowired
private OpenAiEmbeddingModel embeddingModel;
@Test
void contextLoads() {
//1.测试数据
//1.1.用俩查询的文本,国际冲突
String query = "Global conflicts";
//1.2.用来作比较的文本
String[] texts = new String[]{
"哈马斯称加沙下阶段停火谈判仍在进行 以方尚未做出承诺",
"土耳其、芬兰、瑞典与北约代表将继续就瑞典“入约”问题进行谈判",
"日本航空基地水井中检测出有机氟化物超标",
"国家游泳中心(水立方):恢复游泳、嬉水乐园等水上项目运营",
"我国首次在空间站开展舱外辐射生物学暴露实验",
};
//2.向量化
//2.1.先将查询文本向量化
float[] queryVector = embeddingModel.embed(query);
//2.2.再将比较文本向量化,放到一个数组
List<float[]> textVectors = embeddingModel.embed(Arrays.asList(texts));
//3.计算欧式距离
//3.1.把查询文本自己与自己比较,肯定是相似度最高的
System.out.println(VectorDistanceUtils.euclideanDistance(queryVector, queryVector));
//3.2.把查询文本与其他文本比较
for (float[] textVector : textVectors) {
System.out.println(VectorDistanceUtils.euclideanDistance(queryVector, textVector));
}
//4.比较余弦距离
//4.1.把查询文本自己与自己比较,肯定是相似度最高的
System.out.println(VectorDistanceUtils.cosineDistance(queryVector, queryVector));
// 4.2.把查询文本与其它文本比较
for (float[] textVector : textVectors) {
System.out.println(VectorDistanceUtils.cosineDistance(queryVector, textVector));
}
}
}结果:
0.0
1.292770689794132
1.2325630539055
1.3597723730208278
1.3443325897743146
1.3483311697427849
0.0
0.8356279107158756
0.7596057458959865
0.9244903681598415
0.9036148672434118
0.9089984405705567相似度符合预期,有了文本相似比较的办法,知识库的问题就可以解决了。
新的问题:向量模型是帮我们生成向量的,庞大的数据库,谁来帮我们从中比较和检索数据呐?
这就需要用到向量数据库了。
1.3.向量数据库
向量数据库的主要作用有两个:
- 存储向量数据
- 基于相似度检索数据
SpringAI支持很多向量数据库,并且都进行了封装,可以用统一的API去访问:
- Azure Vector Search - The Azure vector store.
- Apache Cassandra - The Apache Cassandra vector store.
- Chroma Vector Store - The Chroma vector store.
- Elasticsearch Vector Store - The Elasticsearch vector store.
- GemFire Vector Store - The GemFire vector store.
- MariaDB Vector Store - The MariaDB vector store.
- Milvus Vector Store - The Milvus vector store.
- MongoDB Atlas Vector Store - The MongoDB Atlas vector store.
- Neo4j Vector Store - The Neo4j vector store.
- OpenSearch Vector Store - The OpenSearch vector store.
- Oracle Vector Store - The Oracle Database vector store.
- PgVector Store - The PostgreSQL/PGVector vector store.
- Pinecone Vector Store - PineCone vector store.
- Qdrant Vector Store - Qdrant vector store.
- Redis Vector Store - The Redis vector store.
- SAP Hana Vector Store - The SAP HANA vector store.
- Typesense Vector Store - The Typesense vector store.
- Weaviate Vector Store - The Weaviate vector store.
- SimpleVectorStore - A simple implementation of persistent vector storage, good for educational purposes.
这些库都实现了统一的接口:VectorStore,因此操作方式一模一样,学会一样,其他的就没问题了。
除了SimpleVectorStore,其他的向量数据库都需要安装部署。
1.3.1.SimpleVectorStore
最后一个SimpleVectorStore向量库是基于内存实现,是一个专门用来测试、教学用的库。
先引入依赖:
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-advisors-vector-store</artifactId>
</dependency>在CommonConfiguration类添加VectorStore的Bean:
@Bean
public VectorStore vectorStore(OpenAiEmbeddingModel embeddingModel) {
return SimpleVectorStore.builder(embeddingModel).build();
}1.3.2.VectorStore接口
接下来就可以使用VectorStore的各种功能。
VectorStore中声明的用法:
public interface VectorStore extends DocumentWriter {
default String getName() {
return this.getClass().getSimpleName();
}
// 保存文档到向量库
void add(List<Document> documents);
// 根据文档id删除文档
void delete(List<String> idList);
void delete(Filter.Expression filterExpression);
default void delete(String filterExpression) { ... };
// 根据条件检索文档
List<Document> similaritySearch(String query);
// 根据条件检索文档
List<Document> similaritySearch(SearchRequest request);
default <T> Optional<T> getNativeClient() {
return Optional.empty();
}
}注意,VectorStore操作向量化的基本单位是Document,我们在使用时需要将自己的知识库分割转换为一个个的Document,然后写入VectorStore。
1.4.文件读取和转换
知识库太大是需要拆分成文档片段,然后再做向量化的,而且SpringAI中向量库接受的是Document类型的文档,也就是说,我们处理文档还要转成Document格式。
不过,文档读取、拆分、转换的动作并不需要我们亲自完成。在SpringAI中提供了各种文档读取的工具,可以参考官网:
比如PDF文档读取和拆分,SpringAI提供了两种默认的拆分原则:
PagePdfDocumentReader:按页拆分,推荐使用ParagraphPdfDocumentReader:按pdf的目录拆分,不推荐,因为很多PDF不规范,没有章节标签
这里我们选择使用PagePdfDocumentReader。
我们需要在pom.xml中引入依赖:
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-pdf-document-reader</artifactId>
</dependency>然后就可以利用工具把PDF文件读取并处理成Document了。
我们在SpringAiDemoApplicationTests中写一个单元测试:
@SpringBootTest
class SpringAiApplicationTests {
//自动注入向量模型
@Autowired
private OpenAiEmbeddingModel embeddingModel;
@Autowired
private VectorStore vectorStore;
@Test
public void testVectorStore(){
//1.创建PDF读取器
Resource resource=new FileSystemResource("java手册.pdf");
PagePdfDocumentReader reader=new PagePdfDocumentReader(
resource,//文件源
PdfDocumentReaderConfig.builder()
.withPageExtractedTextFormatter(ExtractedTextFormatter.defaults())
.withPagesPerDocument(1)
.build()
);
//2.读取PDF文档,拆分为Document
List<Document> documents=reader.read();
//3.写入向量库
vectorStore.add(documents);
//4.搜索
SearchRequest request=new SearchRequest().builder()
.query("数据库索引规范有哪些")
.topK(5)
.similarityThreshold(0.6)
.filterExpression("file_name == 'java手册.pdf'")
.build();
List<Document> docs=vectorStore.similaritySearch(request);
if(docs==null) {
System.out.println("没有搜索到任何内容");
return;
}
for (Document doc : docs) {
System.out.println(doc.getId());
System.out.println(doc.getScore());
System.out.println(doc.getText());
}
}
}测试: 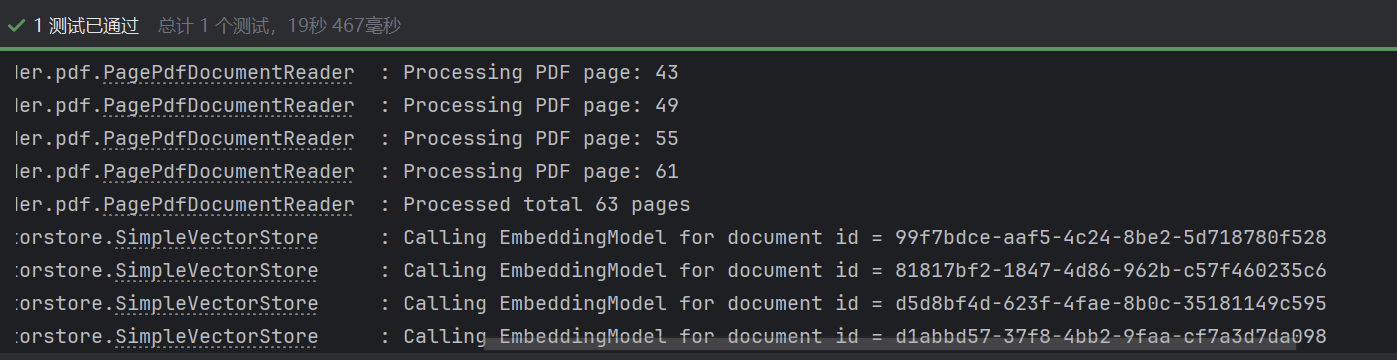
1.5.RAG原理总结
目前已经有了工具:
- PDFReader:读取文档并拆分为片段
- 向量大模型:将文本片段向量化
- 向量数据库:存储向量,检索向量
梳理一下要解决的问题和解决思路:
- 首先需要解决大模型知识限制问题,通过外置知识库解决
- 其次收到大模型上下文限制,知识库不能直接拼接到提示词中
- 然后需要从知识库找到与用户问题相关的一小部分,再组装成提示词
- 最后利用文档阅读器,向量大模型,向量数据库解决问题
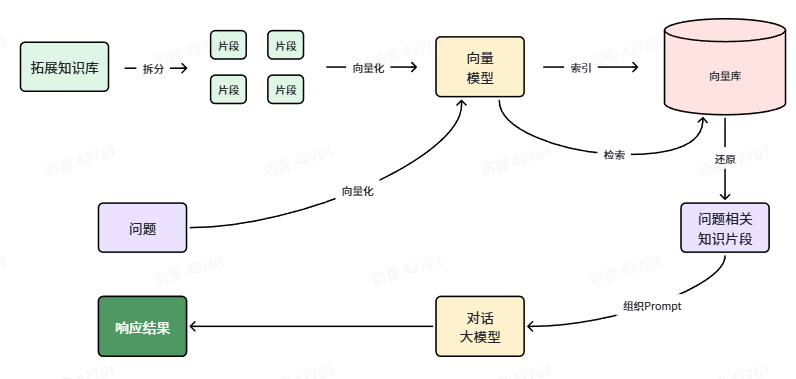
RAG要做的事情就是将知识库分割,然后利用向量模型做向量化,存入向量数据库,然后查询的时候去检索:
第一阶段(存储知识库):
- 将知识库内容切片,分为一个个片段
- 将每个片段利用向量模型向量化
- 将所有向量化后的片段写入向量数据库
第二阶段(检索知识库):
- 每当用户询问AI时,将用户问题向量化
- 拿着问题向量去向量数据库检索最相关的片段
第三阶段(对话大模型):
- 将检索到的片段、用户的问题一起拼接为提示词
- 发送提示词给大模型,得到响应
1.6.目标
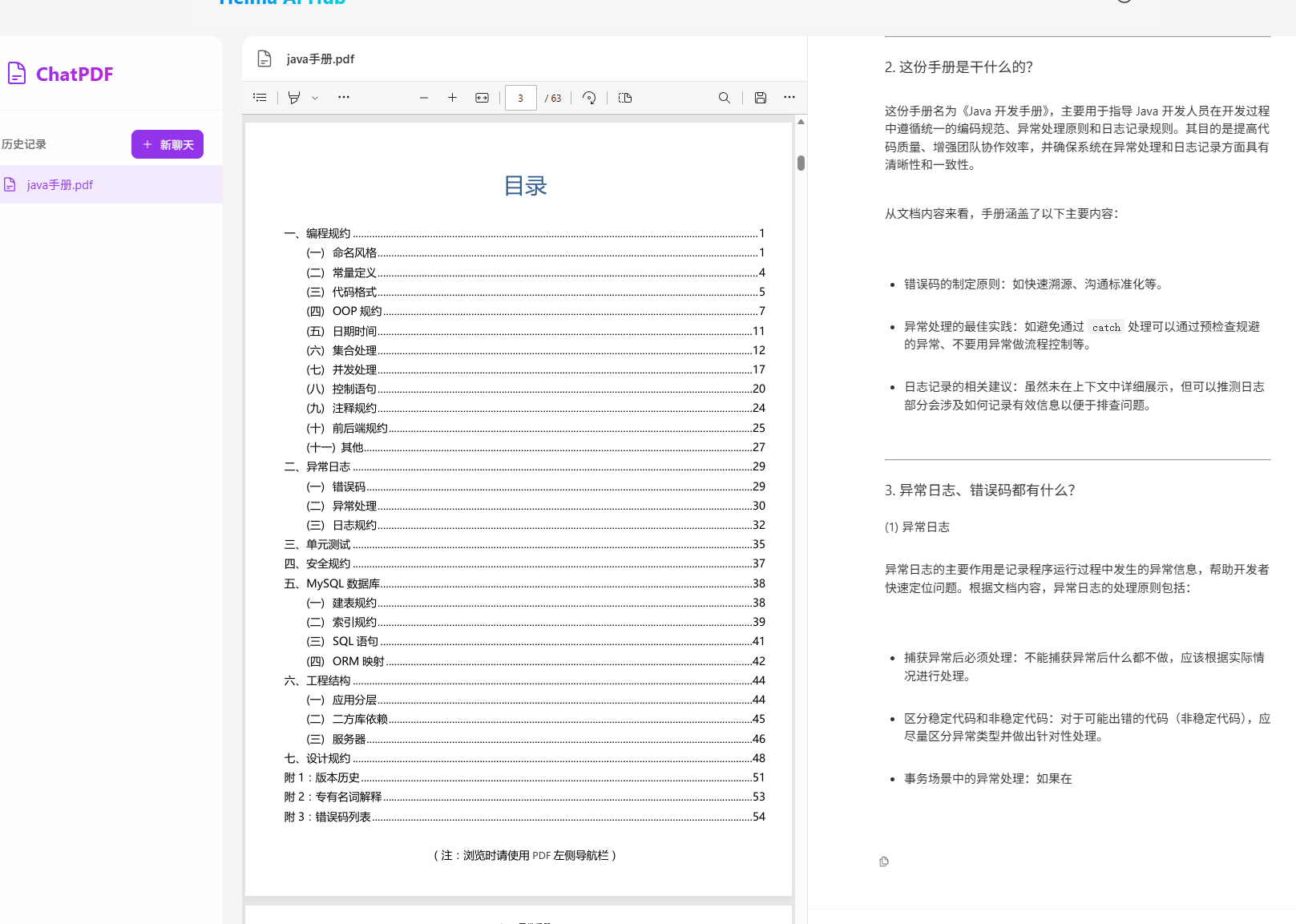
接下来实现个人知识库AI应用,ChatPDF,原网站如下:
这个网站是把个人PDF文件作为知识库,让AI基于PDF内容进行问答,对于学生,研究人员,专业人士来说,非常方便。
2.PDF上传下载、向量化
所有知识库都是PDF形式的,所以需要先实现一个上传PDF的接口,在接口实现以下功能:
- 校验文件格式是否为PDF
- 保存文件信息
- 保存文件(可以是OSS或者本地保存)
- 保存会话ID和文件路径的映射关系(方便查询会话历史的时候再次读取文件)
- 文档拆分和向量化
另外,将来用户查询会话历史,还需要返回pdf文件给前端用于预览,所以需要实现一个下载PDF接口,包含下面功能:
- 读取文件
- 返回文件给前端
2.1.PDF文件管理
由于要实现PDF下载功能,需要记住每一个chatId对应的PDF文件名称。 所以需要定义一个类用来记录chatId与pdf文件之间的映射关系,同时实现基本的文件保存、文件向量化。
先定义接口:
package com.example.ai.service;
import org.springframework.core.io.Resource;
public interface IFileService {
/**
* 保存文件,还要记录chatId与文件的映射关系
* @param chatId 会话id
* @param resource 文件
* @return 上传成功,返回true; 否则返回false
*/ boolean save(String chatId, Resource resource);
/**
* 根据chatId获取文件
* @param chatId 会话id
* @return 找到的文件
*/
Resource getFile(String chatId);
}接着写实现类:
package com.example.ai.service.impl;
import com.example.ai.service.IFileService;
import jakarta.annotation.PostConstruct;
import jakarta.annotation.PreDestroy;
import lombok.AllArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.apache.ibatis.javassist.Loader;
import org.springframework.ai.document.Document;
import org.springframework.ai.reader.ExtractedTextFormatter;
import org.springframework.ai.reader.pdf.PagePdfDocumentReader;
import org.springframework.ai.reader.pdf.config.PdfDocumentReaderConfig;
import org.springframework.ai.vectorstore.SimpleVectorStore;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.core.io.FileSystemResource;
import org.springframework.core.io.Resource;
import org.springframework.stereotype.Service;
import java.io.*;
import java.nio.charset.StandardCharsets;
import java.nio.file.Files;
import java.time.LocalDateTime;
import java.util.List;
import java.util.Objects;
import java.util.Properties;
@Slf4j
@AllArgsConstructor
@Service
public class FileServiceImpl implements IFileService {
//Java专门读写.properties配置文件的工具类
//保存会话id与文件名的对应关系,方便查询会话历史时重新加载文件
private final Properties chatFiles=new Properties();
private final VectorStore vectorStore;
@Override
public boolean save(String chatId, Resource resource) {
//1.保存到本地磁盘
//1.1.获取文件名
String filename=resource.getFilename();
//1.2.用文件名创建保存路径对象
File target=new File(Objects.requireNonNull(filename));
if(!target.exists()){
try {
//1.3.保存文件到路径
Files.copy(resource.getInputStream(),target.toPath());
} catch (IOException e) {
log.error("Failed to save PDF resource",e);
return false;
}
}
//2.保存映射关系
chatFiles.put(chatId,filename);
//3.写入向量库
writeToVectorStore(resource, chatId);
return true;
}
@Override
public Resource getFile(String chatId) {
return new FileSystemResource(chatFiles.getProperty(chatId));
}
@PostConstruct
void init() throws IOException {
//1.创建一个指向本地chat-pdf.properties文件的资源对象
//这个文件用来保存:chatId->pdf文件名
FileSystemResource pdfResource=new FileSystemResource("chat-pdf.properties");
//2.判断chat-pdf.properties文件是否存在
if(pdfResource.exists()) {
try {
//3.读取chat-pdf.properties文件内容
//pdfResource.getInputStream():获取文件输入流
//InputStreamReader(..., UTF_8):按 UTF-8 编码读取
//BufferedReader(...):包装成缓冲字符流,提高读取效率
//chatFiles.load(...):把文件里的 key=value 加载到 Properties 对象中
chatFiles.load(new BufferedReader(new InputStreamReader(pdfResource.getInputStream(), StandardCharsets.UTF_8)));
} catch (IOException e) {
throw new RuntimeException(e);
}
//5.创建一个指向本地chat-pdf.json文件的资源对象
FileSystemResource vectorResource = new FileSystemResource("chat-pdf.json");
if (vectorResource.exists()) {
//将VectorStore转换为 SimpleVectorStore,SimpleVectorStore类型才有load方法
SimpleVectorStore simpleVectorStore = (SimpleVectorStore) vectorStore;
simpleVectorStore.load(vectorResource);
}
}
}
@PreDestroy
private void persistent() {
try {
chatFiles.store(new FileWriter("chat-pdf.properties"), LocalDateTime.now().toString());
if(vectorStore != null && vectorStore instanceof SimpleVectorStore simpleVectorStore) {
simpleVectorStore.save(new File("chat-pdf.json"));
}
} catch (IOException e) {
throw new RuntimeException(e);
}
}
private void writeToVectorStore(Resource resource, String chatId) {
// 1.创建PDF的读取器
PagePdfDocumentReader reader = new PagePdfDocumentReader(
resource, // 文件源
PdfDocumentReaderConfig.builder()
.withPageExtractedTextFormatter(ExtractedTextFormatter.defaults())
.withPagesPerDocument(1) // 每1页PDF作为一个Document
.build()
);
// 2.读取PDF文档,拆分为Document
List<Document> documents = reader.read();
documents.forEach(document -> document.getMetadata().put("chat_id", chatId));
// 3.写入向量库
vectorStore.add(documents);
}
}注意:由于选择了基于内存的SimpleVectorStore,重启就会丢失向量数据。所以这里依然是将pdf文件与chatId的对应关系、VectorStroe都持久到了磁盘。 实际开发中,如果选了RedisVectorStore,或者CassandraVectorStore,则无需自己持久化,但是chatId和PDF之间对应的关系还是需要自己维护。
2.2.上传文件响应结果
由于前端文件上传需要返回响应结果,先定义一个Result类
package com.example.ai.entity.vo;
import lombok.Data;
import lombok.NoArgsConstructor;
@Data
@NoArgsConstructor
public class Result {
private Integer ok;
private String msg;
private Result(Integer ok, String msg) {
this.ok = ok;
this.msg = msg;
}
public static Result ok() {
return new Result(1,"ok");
}
public static Result fail(String msg){
return new Result(0,msg);
}
}2.3.文件上传、下载
接下来实现上传和下载文件接口
创建PdfController类:
package com.example.ai.controller;
import com.example.ai.entity.vo.Result;
import com.example.ai.service.IFileService;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.core.io.Resource;
import org.springframework.http.MediaType;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.*;
import org.springframework.web.multipart.MultipartFile;
import java.io.IOException;
import java.net.URLEncoder;
import java.nio.charset.StandardCharsets;
import java.util.Objects;
@Slf4j
@RequiredArgsConstructor
@RestController
@RequestMapping("/ai/pdf")
public class PdfController {
private final IFileService fileService;
private final ChatClient pdfChatClient;
/**
* 文件上传
*/
@RequestMapping("/upload/{chatId}")
public Result uploadPdf(@PathVariable String chatId, @RequestParam("file") MultipartFile file) {
try {
//1.校验文件是否为pdf格式
if (!Objects.equals(file.getContentType(), "application/pdf")) {
return Result.fail("只能上传pdf文件");
}
//2.保存文件
boolean success = fileService.save(chatId, file.getResource());
if (!success) {
return Result.fail("保存文件失败!");
}
return Result.ok();
} catch (Exception e) {
log.error("Failed to upload PDF.", e);
return Result.fail("上传文件失败");
}
}
/**
* 文件下载
*/
@GetMapping("/file/{chatId}")
public ResponseEntity<Resource> download(@PathVariable("chatId") String chatId) throws IOException {
// 1.读取文件
Resource resource = fileService.getFile(chatId);
if (!resource.exists()) {
return ResponseEntity.notFound().build();
}
// 2.文件名编码,转成URL安全格式
String filename = URLEncoder.encode(Objects.requireNonNull(resource.getFilename()), StandardCharsets.UTF_8);
// 3.返回文件
return ResponseEntity.ok()
.contentType(MediaType.APPLICATION_OCTET_STREAM)
.header("Content-Disposition", "attachment; filename=\"" + filename + "\"")
.body(resource);
}
}2.4.上传限制
SpringMvc默认有文件大小限制,只有10M,很多知识库文件都会超过这个值,所以我们需要修改配置,增加文件上传允许的上限。
修改application.yaml文件,添加配置:
spring:
servlet:
multipart:
max-file-size: 30MB
max-request-size: 40MB2.5.暴露响应头
默认情况下跨域请求响应头是不暴露的,这样前端就拿不到下载的文件名,所以选哟修改CORS配置,暴露响应头:
package com.example.ai.config;
import org.springframework.context.annotation.Configuration;
import org.springframework.web.servlet.config.annotation.CorsRegistry;
import org.springframework.web.servlet.config.annotation.WebMvcConfigurer;
@Configuration
public class MvcConfiguration implements WebMvcConfigurer {
public void addCorsMappings(CorsRegistry registry) {
registry.addMapping("/**")
.allowedOrigins("*")
.allowedMethods("*")
.allowedHeaders("*")
.exposedHeaders("Content-Disposition");
}
}3.配置ChatClient
理论上来说:每次与AI的完整流程是:
- 将用户问题利用大模型做向量化,使用OpenAiEmbeddingModel
- 去向量数据库检索相关文档,使用VectorStore
- 拼接提示词,发给大模型
- 解析响应结果
SpringAi同样基于AOP技术帮我们完成了全部流程,用的是名为QuestionAnswerAdvisor的Advisor。只需要把VectorStore配置到Advisor即可。
给ChatPDF单独定义一个ChatClient:
@Bean
public ChatClient pdfChatClient(OpenAiChatModel model, ChatMemory chatMemory,VectorStore vectorStore){
return ChatClient.builder(model)
.defaultAdvisors(
SimpleLoggerAdvisor.builder().build(),
MessageChatMemoryAdvisor.builder(chatMemory).build(),
QuestionAnswerAdvisor
.builder(vectorStore)
.searchRequest(
SearchRequest.builder()//向量检索的请求参数
.similarityThreshold(0.5d) //相似度阈值
.topK(2) //返回文档片段数量
.build()
).build()
).build();
}我们也可以自己自定义RAG查询的流程,不使用Advisor,具体可参考官网: [Retrieval Augmented Generation](Retrieval Augmented Generation :: Spring AI Reference)
4.对话接口
最后对接前端,修改PdfController,添加接口:
@RequestMapping(value = "/chat", produces = "text/html;charset=UTF-8")
public Flux<String> chat(String prompt, String chatId) {
recordService.saveRecord("pdf", chatId);
return pdfChatClient
.prompt(prompt)
.advisors(a -> a.param(ChatMemory.CONVERSATION_ID, chatId))
.advisors(a -> a.param(QuestionAnswerAdvisor.FILTER_EXPRESSION, "chat_id == '"+chatId+"'"))
.stream()
.content();
}测试: 上传pdf,跟ai进行内容交互。