Feed流实现方案
当用户关注了博主,并且博主发布了动态时,我们需要将这些动态数据推送给用户。这种需求通常被称为Feed流,也可以理解为关注推送,直译为“投喂”。目的时为用户提供沉浸式体验,通过无限下拉刷新来获取最新动态消息。
对于传统模式的内容解锁:我们需要用户去搜索引擎或是其他方式解锁想要看的内容

对于新型Feed流效果:不需要用户自己去检索消息,而是系统分析用户想要什么,然后直接把内容推送给用户,从而使用户更加节约时间,不用主动寻找。

Feed流产品实现有两种常见模式:
Timeline:不做内容筛选,简单的按照内容发布时间排序,常用于好友或关注。例如朋友圈。
- 优点:信息全面,不会有缺失。并且实现相对简单。
- 缺点:信息噪音较多,用户不一定感兴趣,内容获取效率低。
智能排序:利用只能算法屏蔽掉违规的、用户不感兴趣的内容。推送用户感兴趣信息来吸引用户。例如抖音、快手。 - 优点:头为用户感兴趣信息,用户粘度高,容易沉迷
- 缺点:如果的算法不准确,可能起到反作用
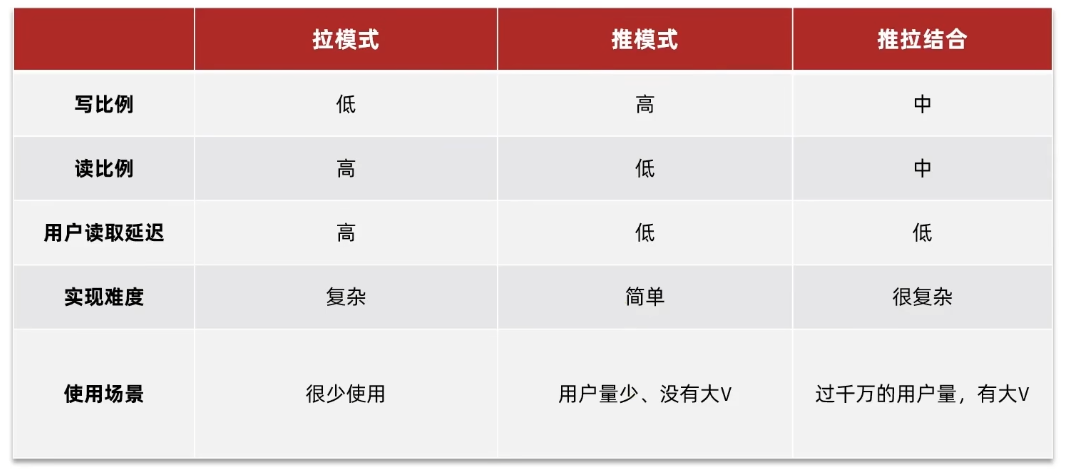
我们针对好友的操作采用的就是Timeline方式,只需要拿到我们关注用户的信息,然后按照时间排序即可,因此采用Timeline的模式。该模式实现方案有三种:
- 拉模式
- 推模式
- 推拉结合
拉模式
也叫做读扩散。在拉模式中,终端用户或应用程序主动发送请求来获取最新的数据流。它是一种按需获取数据的方式,用户可以在需要时发出请求来获取新数据。在Feed流中,数据提供方将数据发布到实时数据源中,而终端用户或应用程序通过订阅或请求来获取新数据。
例如,当张三和李四和王五发了消息后,都会保存在自己的邮箱中,假设赵六要读取信息,那么他会从读取他自己的收件箱,此时系统会从他关注的人群中,把他关注人的信息全部都进行拉取,然后在进行排序
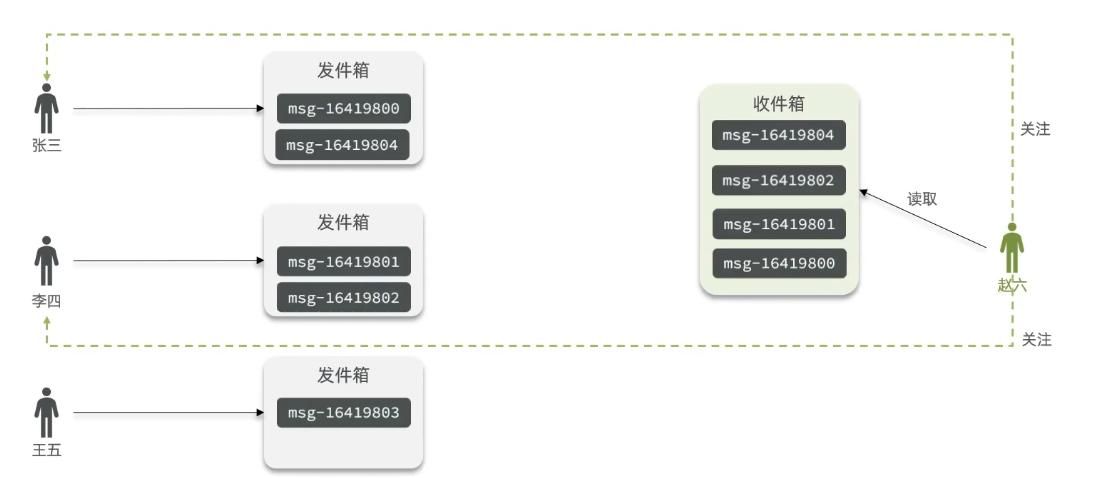
优点:节约空间,因为赵六在读信息时,并没有重复读取,而且读取完之后可以把他的收件箱进行清除。
缺点:延迟较高,当用户读取数据时才去关注的人里边去读取数据,假设用户关注了大量的用户,那么此时就会拉取海量的内容,对服务器压力巨大。
推模式
也叫做写扩散。在推模式中,数据提供方主动将最新的数据推送给终端用户或应用程序。数据提供方会实时地将数据推送到终端用户或应用程序,而无需等待请求。
推模式是没有写邮箱的,当张三写了一个内容,此时会主动的把张三写的内容发送到他的粉丝收件箱中去,假设此时李四再来读取,就不用再去临时拉取了
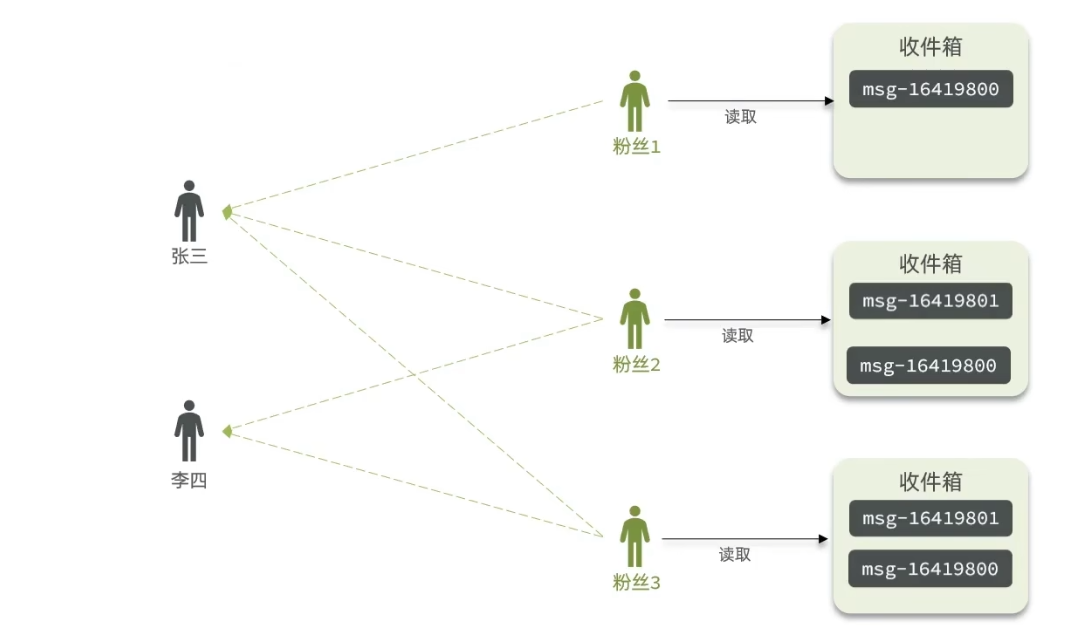
优点:时效快,不用临时拉取
缺点:内存压力大,假设一个大V写信息,很多人关注他, 就会写很多份数据到粉丝那边去
推拉结合模式
也叫做读写混合,兼具推和拉两种模式的优点。在推拉结合模式中,数据提供方会主动将最新的数据推送给终端用户或应用程序,同时也支持用户通过拉取的方式来获取数据。这样可以实现实时的数据更新,并且用户也具有按需获取数据的能力。
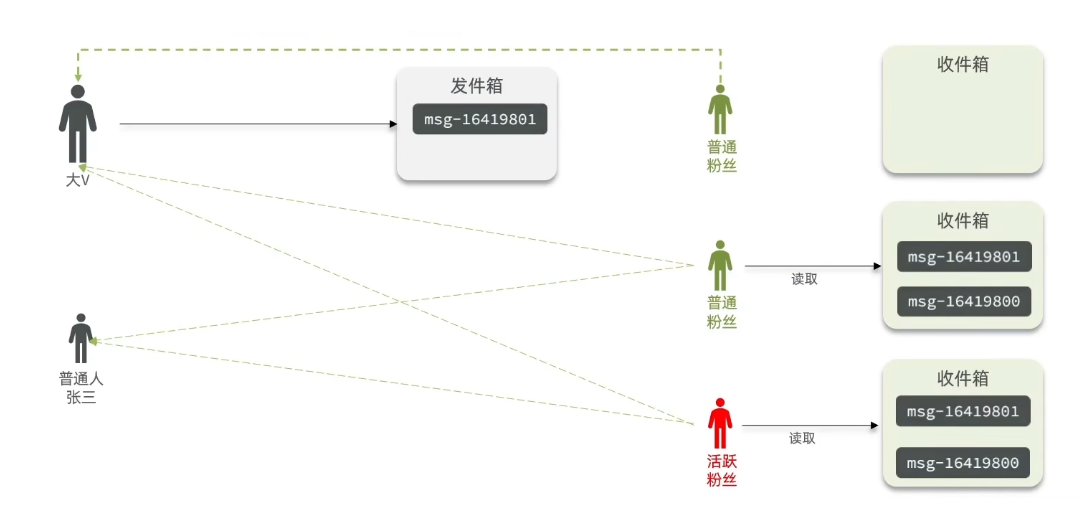
推拉结合是一种这种方案。 对于发件人:
- 普通人:采用写扩散的方式,直接把数据写入到他的粉丝中去,因为普通人粉丝关注量小,这样做没有压力。
- 大V:将数据先写入到一份邮箱去,然后再写一份到活跃粉丝邮箱里。 对于收件人:
- 活跃粉丝:大V和普通人发的都会直接写入到自己收件箱。
- 普通粉丝:上线不频繁,等上线时,再去发件箱拉取数据
推送到粉丝邮件箱
需求:
- 增加新增探店笔记业务,在保存blog到数据库的同时,同送到粉丝收件箱
- 收件箱满足可以根据时间戳排序,必须用Redis的数据结构实现
- 查询收件箱数据时,可以实现分页查询
Feed流中的分页的问题:Feed流数据会不断更新,可能随时发生变化,所以数据的角标也在变化,因此不能采用传统分页模式
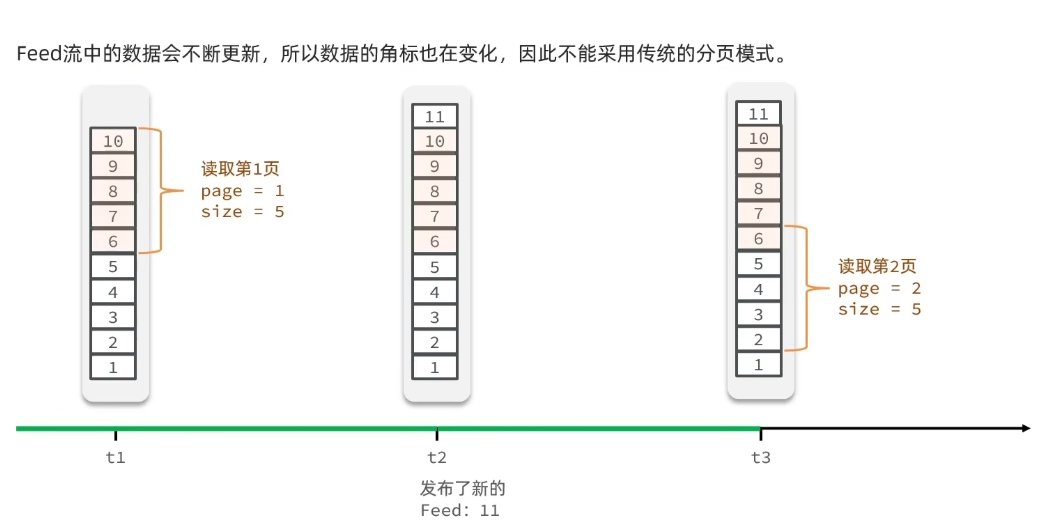
假设此时是t1时刻,page=1,size=5,我们拿到的就是10~6这几条数据,假设t2时刻又新发布了一条数据11,在t3时刻,我们读取第二页,传入参数page=2,size=5,南无此时读取到的第二页实际上是从6开始,查询6~2,那我们就读到了重复的数据6,所以feed流的分页不能采取传统方式来做。
Feed流的滚动分页:因为我们存的数据是有序的,可以用翻页游标IastId记录每次操作的最后一条,然后从这个位置开始去读取数据,这样查询不依赖角标,因此不会收到数据角标变化带来的影响。
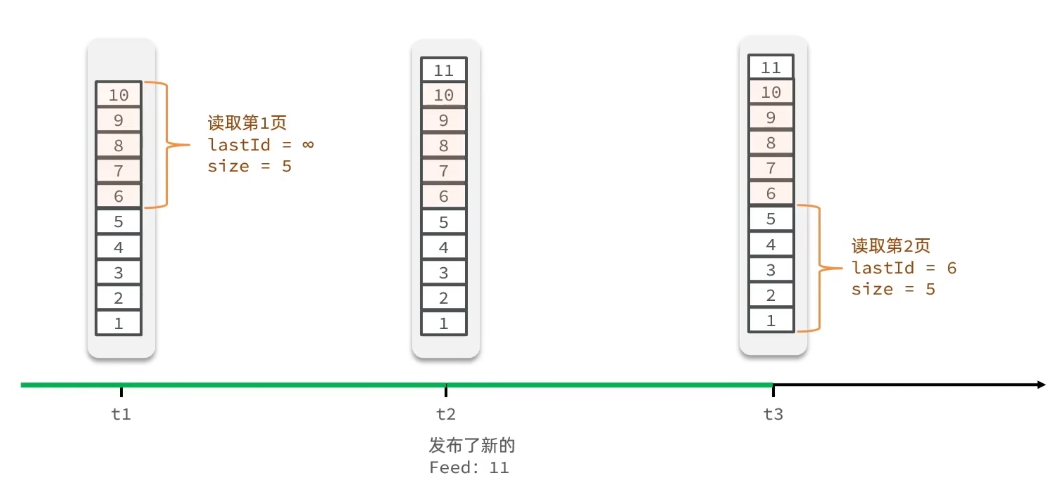
从t1时刻开始,读取第一页数据,拿到10~6,然后记录下当前最后一次拿取的记录,IastId就是6,t2时刻发布新数据11放到最前面,不会影响我们之前记录的6,t3时刻再来查询第二页,第二页起始位置从下一个5开始湖区哦v,就拿到了5~1的记录
之前分析过,虽然List和SortedSet都能支持排序,但List结构依赖角标查询,因此不支持滚动分页。而SortedSet会按照score值排序,数据排序完会有一个排名,如果按排名查询,那和角标查询没有区别,而SortedSet还支持按score值的范围进行查询,因此我们可以采用SortedSet来做,按时间戳从大到小降序排列后进行范围查询,查询时每次记录最小的时间戳,下次查询时找比这个时间戳次小的,从这里开始,从而实现滚动分页。
- 保存笔记,并推送给所有粉丝
@Resource
private IFollowService followService;
/**
* 发布探店笔记并推送给粉丝。
*
* 作用:
* 1.获取登录用户;
* 2.保存探店笔记;
* 3.查询笔记作者的所有粉丝select*fromtb_followwherefollow;
* 4.推送笔记id给所有粉丝;
* 5.获取粉丝id;
*
* @param blog当前博客对象
* @return处理结果
*/
@Override
public Result saveBlog(Blog blog) {
//1.获取登录用户
UserDTO user = UserHolder.getUser();
blog.setUserId(user.getId());
//2.保存探店笔记
boolean isSuccess=save(blog);
if(!isSuccess){
return Result.fail("新增笔记失败");
}
//3.查询笔记作者的所有粉丝select * from tb_follow where follow_user_id=?
List<Follow> follows=followService.query().eq("follower_id",user.getId()).list();
//4.推送笔记id给所有粉丝
for (Follow follow:follows){
//4.1.获取粉丝id
Long id=follow.getId();
//4.2.推送
String key="feed:"+user.getId();
stringRedisTemplate.opsForZSet().add(key,blog.getId().toString(),System.currentTimeMillis());
}
//5.返回id
return Result.ok(blog.getId());
}- 测试功能 发布笔记后,粉丝邮箱出现推送笔记
实现滚动分页查询
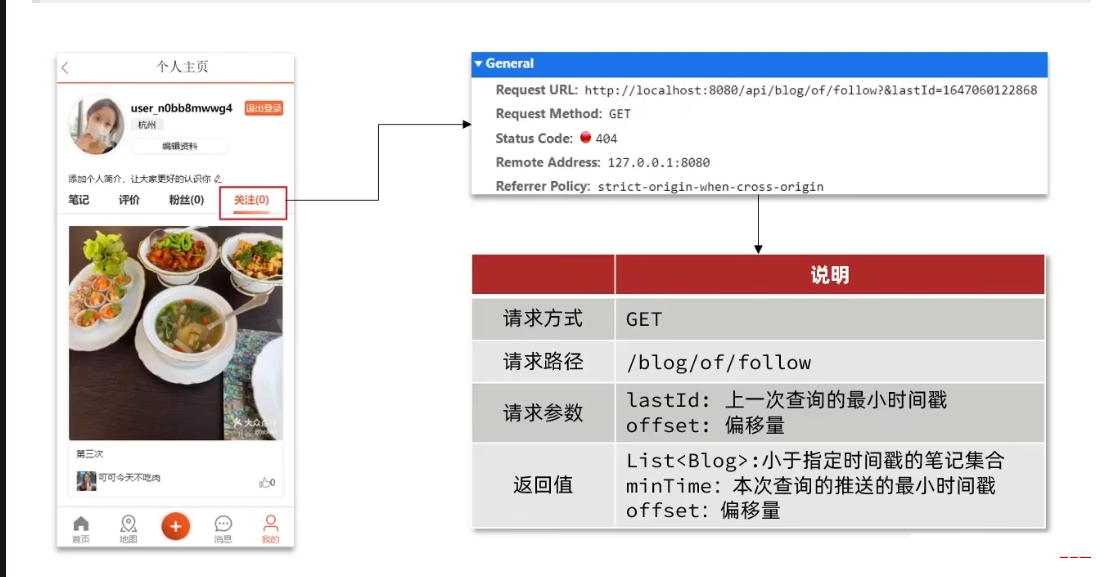
需求:在个人主页的“关注”卡片中,查询并展示推送的Blog信息
ZRANGE是按照角标从小到大排序:
ZREVRANGE是按照角标从大到小排序
ZREVRANGEBYSCORE是按照分数从大到小排序
参数:
- max:分数最大值
- min:分数最小值
- offset:偏移量
- count:查的数量
滚动查询:每次记住上一次查询的最小值,将上一次的最小值作为下一次查询的最大值
ZREVRANGEBYSCORE z1 1000 0 WITHSCORES LIMIT 0 3
#从z1里查score在0~1000之间的数据
#按score从大到小排
#从第0条开始
#查3条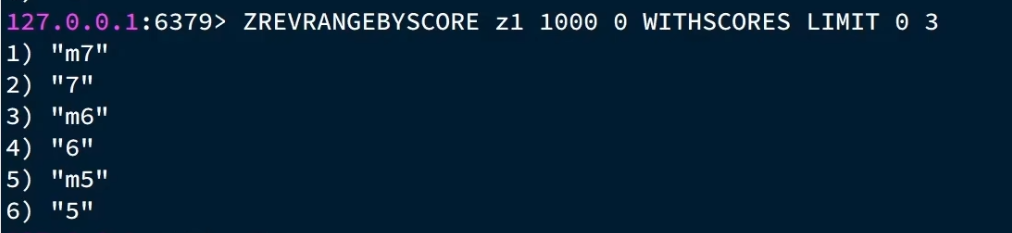
ZREVRANGEBYSCORE z1 6 0 WITHSCORES LIMIT 1 3
#查score<=6的数据
#跳过1条
#查3条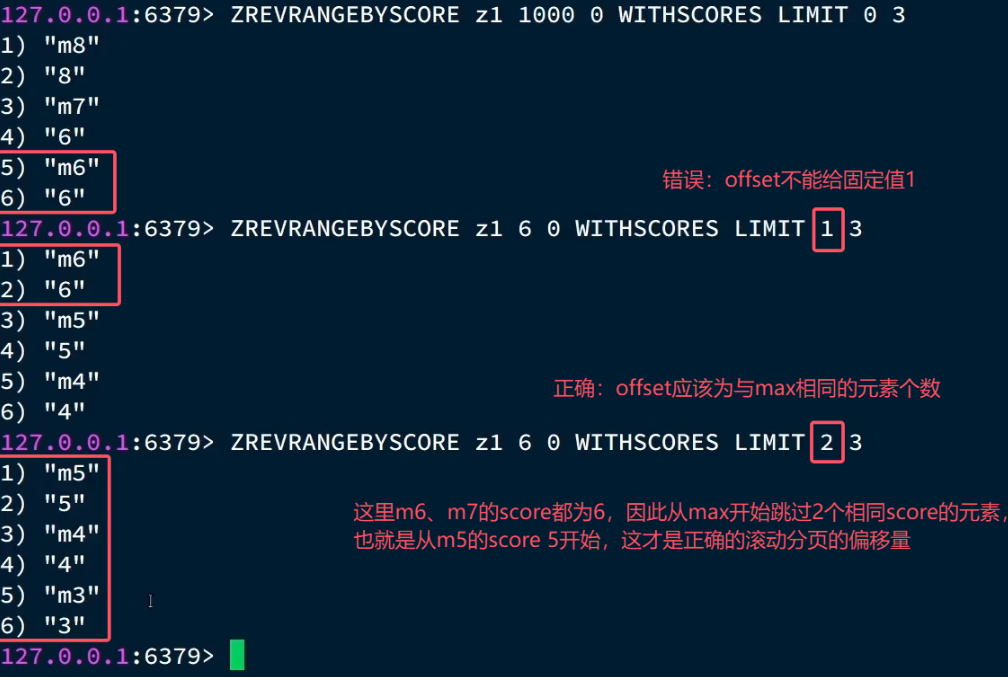 第一次查询最小score为6并且有两个score为6的数据,所以第二次查询offset应该为2,表示跳过这两条数据
第一次查询最小score为6并且有两个score为6的数据,所以第二次查询offset应该为2,表示跳过这两条数据
在使用ZREVRANGEBYSCORE key max min LIMIT offset count实现滚动分页时:
min表示查询分数下限,一般固定为0或一个足够小的值,用来保证能查到更早的数据;count表示每次查询的数量,由前端或后端分页大小决定,通常固定不变。- 第一次查询时,
max取当前时间戳,offset取0,表示从最新数据开始查询。 - 之后每次查询时,
max取上一次查询结果中的最小分数,也就是上一页最后一批数据的最小时间戳;offset用来跳过已经查询过的、并且分数等于当前max的元素,避免因为多个元素分数相同而出现重复数据。 - 如果上一页结果中最小分数为
minTime,并且有n个元素的分数等于minTime,那么下一次查询时:
max = minTime
offset = n- ScrollResult:封装滚动分页查询结果
@Data
public class ScrollResult {
private List<?> list;
private Long minTime;
private Integer offset;
}- BlogServiceImpl
/**
* 滚动分页查询关注用户的探店笔记。
*
* 作用:
* 1.获取当前用户;
* 2.查询收件箱ZREVRANGEBYSCOREkeyMaxMinLIMIToffsetc;
* 3.非空判断;
* 4.解析数据:blogId、minTime(时间戳)、offset;
* 5.获取id;
*
* @param max本次查询的最大时间戳
* @param offset偏移量
* @return处理结果
*/
@Override
public Result queryBlogOfFollow(Long max, Integer offset) {
//1.获取当前用户
Long userId=UserHolder.getUser().getId();
//2.查询收件箱
String key="feed:"+userId;
Set<ZSetOperations.TypedTuple<String>> typedTuples = stringRedisTemplate.opsForZSet().rangeByScoreWithScores(key, 0, max, offset, 2);
//3.非空判断
if(typedTuples==null||typedTuples.isEmpty()){
return Result.ok();
}
//4.解析数据:blogId、minTime(时间戳)、offset
List<Long> ids=new ArrayList<>(typedTuples.size());
long minTime=0;
int os=1;
for(ZSetOperations.TypedTuple<String> tuple:typedTuples){
//4.1.获取id
ids.add(Long.valueOf(tuple.getValue()));
//4.2.获取分数(时间戳)
long time=tuple.getScore().longValue();
if(time==minTime){
os++;
}else{
minTime=time;
os=1;
}
}
//5.根据id查询blog
String idStr = StrUtil.join(",",ids);
List<Blog> blogs=query().in("id",ids).last("ORDER BY FIELD(id,"+idStr+")").list();
for(Blog blog:blogs){
queryBlogUser(blog);
isBlogLiked(blog);
}
//6.封装并返回
ScrollResult r=new ScrollResult();
r.setList(blogs);
r.setOffset(os);
r.setMinTime(minTime);
return Result.ok(r);
}- 测试功能 用户发布笔记后,粉丝成功查看笔记,上刷重新加载页面获取最新时间戳,下拉获取旧数据
