由于我们的缓存的数据源来自于数据库,而数据库的数据是会发生变化的,因此,如果当数据库中数据发生变化,而缓存却没有同步 ,此时就存在 缓存数据一致性问题 。
缓存数据一致性问题的根本原因是 缓存和数据库中的数据不同步 。
那么我们该如何让 缓存 和 数据库中的数据尽可能的保证同步?首先需要选择一个比较好的缓存更新策略。
常见的缓存更新策略
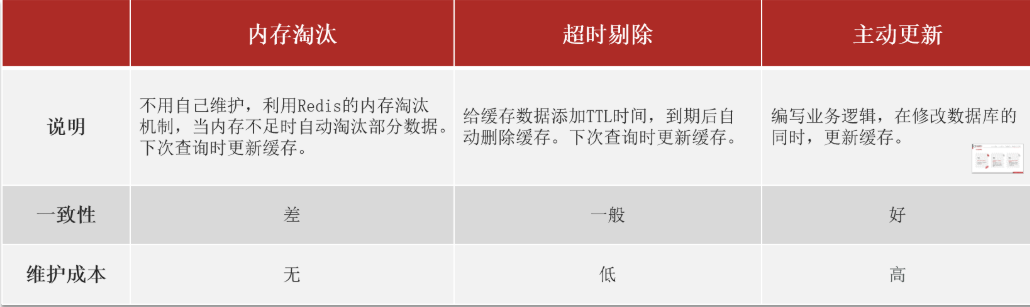
内存淘汰(自动): 利用 Redis的内存淘汰机制 实现缓存更新,Redis的内存淘汰机制是当Redis发现内存不足时,会根据一定的策略自动淘汰部分数据。
Redis中常见的淘汰策略:
noeviction(默认):当达到内存限制并且客户端尝试执行写入操作时,Redis 会返回错误信息,拒绝新数据的写入,保证数据完整性和一致性
allkeys-lru:从所有的键中选择最近最少使用(Least Recently Used,LRU)的数据进行淘汰。即优先淘汰最长时间未被访问的数据
allkeys-random:从所有的键中随机选择数据进行淘汰
volatile-lru:从设置了过期时间的键中选择最近最少使用的数据进行淘汰
volatile-random:从设置了过期时间的键中随机选择数据进行淘汰
volatile-ttl:从设置了过期时间的键中选择剩余生存时间(Time To Live,TTL)最短的数据进行淘汰**超时剔除(半自动):**手动给缓存数据设置过期时间TTL,到期后Redis自动删除超时的数据。
**主动更新(手动):**手动编码实现缓存更新,在修改数据库的同时更新缓存。我们可以手动调用方法把缓存删掉,通常用于解决缓存和数据库不一致问题。
缓存更新策略的选择,应该看业务场景对数据一致性的的需求:
- 低一致性需求:使用Redis自带的内存淘汰机制 + 超时更新。
- 高一致性需求:主动更新,并以超时剔除作为兜底方案。
主动更新策略的三种方案
双写方案(Cache Aside Pattern):人工编码方式,缓存调用者在更新完数据库后再去更新缓存。维护成本高,灵活度高。 读写穿透方案(Read/Write Through Pattern):将数据库和缓存整合为一个服务,由服务来维护缓存与数据库的一致性,调用者无需关心数据一致性问题,降低了系统的可维护性,但是实现困难,也没有较好的第三方服务供我们使用。 写回方案(Write Behind Caching Pattern):调用者只操作缓存,其他独立的线程去异步处理数据库,将待写入的数据放入一个缓存队列,在适当的时机,通过批量操作或异步处理,将缓存队列中的数据持久化到数据库,实现最终一致。

双写方案 和 读写穿透方案 在写入数据时都会直接更新缓存,以保持缓存和底层数据存储的一致性。
写回方案 延迟了缓存的更新操作,又由于异步更新机制,将多次对数据库的写合并成一次写,将多次对数据库的更新以最后一次更新的结果作为有效数据,去更新数据库。
主动更新策略中三种方案的应用场景 :
双写方案 较适用于读多写少的场景,数据的一致性由应用程序主动管理 读写穿透方案 适用于数据实时性要求较高、对一致性要求严格的场景
写回方案 适用于追求写入性能的场景,对数据的实时性要求相对较低、可靠性也相对低,延迟写入的数据是在内存中的。
综合考虑使用方案一,虽然双写方案需要缓存调用者手动编码维护,但可控性更高。
双写方案问题
使用双写方案操作缓存和数据库时有三个问题需要考虑:
是删除缓存还是更新缓存?(两种缓存更新方案,选择效率更高的)
| 方案 | 操作逻辑 | 缺点/优点 | 评价 |
|---|---|---|---|
| 更新缓存 | 每次更新数据库时,同步更新缓存。 | 缺点:无效写操作多。 如果发生100次写操作但没有读操作,这100次写入缓存都会白费服务器资源(写多读少场景极度消耗性能)。 | ❌ 不推荐 |
| 删除缓存 | 更新数据库时,直接将旧缓存删掉。等下次有读请求时再查库、写入新缓存。 | 优点:效率更高,按需加载。 避免了无效更新,只有当数据真正被访问时才会去构建缓存。 | ✅ 推荐 |
原子性保证:如何让缓存和数据库操作同成功/同失败?
结论:根据系统架构选择对应的事务控制方案。
单体架构系统: 利用本地事务(如Spring的
@Transactional),将更新数据库和删除缓存的操作包裹在同一个事务中。分布式架构系统: 由于缓存和数据库通常是独立节点,需要利用 分布式事务 方案(如TCC、Seata、基于消息队列的最终一致性方案)来保证原子性。
并发顺序:先操作数据库,还是先操作缓存?
结论:推荐“先更新数据库,再删除缓存”。
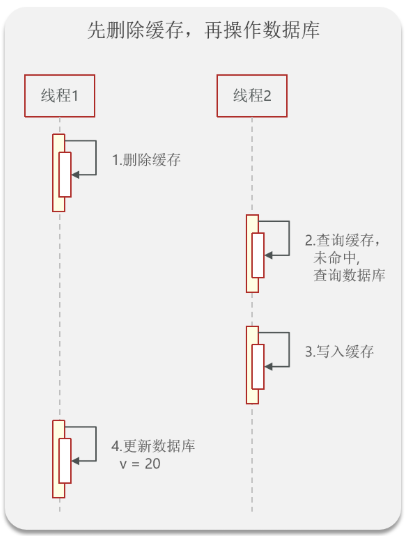
1. 先删缓存,再更数据库(高概率出现脏数据)
致命缺陷: 读写速度差导致脏数据长时间驻留缓存。
并发错误场景:
【线程A】要更新数据,先删除了缓存,准备去更新数据库(较慢)。
【线程B】来查询数据,发现缓存没了,去查数据库,查到了旧数据。
【线程B】把查到的旧数据写入缓存。
【线程A】终于完成了数据库更新(新数据)。
- 最终后果: 数据库里是新数据,缓存里是旧数据,且在缓存过期前,所有请求读到的都是错的。同时,这种做法容易在删缓存的瞬间引发缓存击穿。
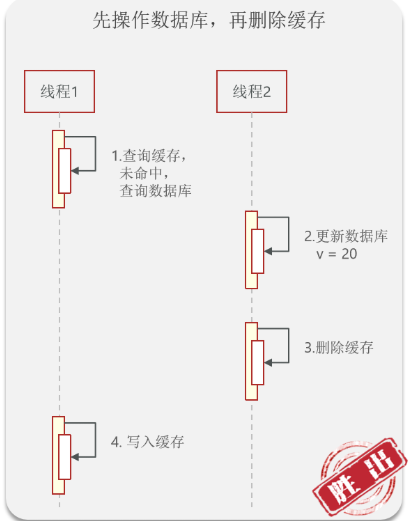
2. 先更数据库,再删缓存(极低概率出现脏数据)
核心优势: 发生并发冲突的条件极其苛刻,日常几乎不会触发。
罕见并发错误场景(需同时满足):
缓存恰好刚刚过期失效。
【线程A】来查询,查不到缓存,去数据库查到了旧数据,正准备写缓存(微秒级)。
此时【线程B】突然介入,更新了数据库,并且删除了缓存。
【线程A】恢复执行,把刚才拿到的旧数据写入了缓存。
- 为什么说概率极低? 因为【线程A】写缓存的速度极快(内存操作)。【线程B】要想在【线程A】查完库到写缓存这极其短暂的“空隙”内,完成一整套耗时的“写数据库 + 删缓存”操作,在物理时间上几乎是不可能的。