1.模型介绍
大模型应用开发并不是在浏览器跟AI聊天,而是通过访问模型对外暴露的API接口,实现与模型的交互。
因此,企业首先需要有一个可访问的大模型,通常有三种选择:
- 使用开放的大模型API
- 在云平台部署私有大模型
- 在本地服务器部署私有大模型
使用开放大模型API的优缺点如下:
- 优点:
- 没有部署和维护成本,按调用收费
- 缺点:
- 依赖平台方,稳定性差
- 长期使用成本较高
- 数据存储在第三方,有隐私和安全问题
云平台部署私有模型:
- 优点:
- 前期投入成本低
- 部署和维护方便
- 网络延迟较低
- 缺点:
- 数据存储在第三方,有隐私和安全问题
- 长期使用成本高
本地部署私有模型:
- 优点:
- 数据完全自主掌控,安全性高
- 不依赖外部环境
- 虽然短期投入大,但长期来看成本会更低
- 缺点:
- 初期部署成本高
- 维护困难
2.调用大模型
学习大模型应用开发,需要掌握模型的API接口规范。
目前大多数大模型都遵循OpenAI的接口规范,是基于HTTP协议的接口。因此请求路径、参数、返回值信息都是类似的,可能会有一些小的差别。OpenAI 兼容不代表完全一样。不同平台在模型名称、特殊参数、工具调用、推理内容、流式事件格式、错误码等方面可能有差异,实际开发仍然要看官方文档。
2.1.大模型接口规范
以DeepSeek官方给出的文档为例:
from openai import OpenAI
client = OpenAI(api_key="<DeepSeek API Key>", base_url="https://api.deepseek.com")
response = client.chat.completions.create(
model="deepseek-chat",
messages=[
{"role": "system", "content": "You are a helpful assistant"},
{"role": "user", "content": "Hello"},
],
stream=False
)
print(response.choices[0].message.content)2.1.1.接口说明
- 请求方式:通常是POST,因为要传递JSON风格的参数
- 请求路径:与平台有关
- DeepSeek官方平台:deepseek
- 阿里云百炼平台:[aliyun](https://dashscope.aliyuncs.com/compatible-mode/v1
- 本地ollama部署的模型:
http://localhost:11434
- 安全校验:开放平台都需要提供API_KEY来校验权限,本地ollama则不需要
- 请求参数:参数很多,比较常见的有:
- model:要访问的模型名称
- messages:发送给大模型的消息,是一个数组
- stream:true,代表响应结果流式返回;false,代表响应结果一次性返回,但需要等待
- temperature:取值范围[0:2),代表大模型生成结果的随机性,越小随机性越低。DeepSeek-R1不支持
注意,这里请求参数中的messages是一个消息数组,而且其中的消息要包含两个属性:
- role:消息对应的角色
- content:消息内容
其中消息的内容,也被称为提示词,也就是发给大模型的指令。
2.1.2.提示词角色
通常消息的角色有三种:
| 角色 | 描述 | 示例 |
|---|---|---|
| system | 优先于user指令之前的指令,也就是给大模型设定角色和任务背景的系统指令 | 你是一个乐于助人的编程助手,你以小团团的风格来回答用户的问题。 |
| user | 终端用户输入的指令(类似于你在ChatGPT聊天框输入的内容) | 写一首关于Java编程的诗 |
| assistant | 由大模型生成的消息,可能是上一轮对话生成的结果 | 注意,用户可能与模型产生多轮对话,每轮对话模型都会生成不同结果。 |
| System类型消息影响了后续AI会话的行为逻辑。 |
当我们询问AI对话产品“你是谁”这个问题的时候,每一个AI的回答都不一样,这是因为AI对话产品并不是直接把用户的提问发给LLM,通常都会在user提问前通过System消息发给模型设定好背景:
示例:
## Role
System: 你是一家名为《黑马程序员》的职业教育培训公司的智能客服,你的名字叫小黑。请以友好、热情的方式回答用户问题。
## Example
User: 你好
Assisant: 你好,我是小黑,很高兴认识你!😊 你是想了解我们的课程信息,还是有其他关于职业培训的问题需要咨询呢?无论什么问题,我都会尽力帮你解答哦!2.1.3.会话记忆功能
为什么要把历史消息都放入Message中,形成一个数组?
因为大模型是没有记忆的,我们调用API与接口和大模型对话时,每一次对话信息都不会保留,多次对话之间是没有关联的。
Message数组:我们每一次发送请求,把历史对话中每一轮的User消息、Assistant消息都封装到Messages数组中,一起发送给大模型,这样大模型就会根据历史对话消息进一步回答,就像是拥有了记忆一样。
示例:
System: 你是一家名为《黑马程序员》的职业教育培训公司的智能客服,你的名字叫小黑。请以友好、热情的方式回答用户问题。
User: 你好,我是小明
Assisant: 你好小明,我是小黑,很高兴认识你!😊 你是想了解我们的课程信息,还是有其他关于职业培训的问题需要咨询呢?无论什么问题,我都会尽力帮你解答哦!
User: 帮我写一个跟我名字有关的诗
Assisant: 好的,下面是以你的名字写的诗:
小明啊小明,名字真明亮,
如晨曦初现,驱散了黑暗。
心中有火焰,智慧放光芒,
在求知路上,你是那最亮的星。
像清澈溪流,绕过知识山岗,
带着勇气和希望,不断向前方。
你的每一步,都闪耀着坚强,
未来的大门,正为你而敞开。
无论走到哪,世界因你更晴朗,
小明啊小明,愿你永远这样,
保持那份纯真,还有对梦想的向往,
人生的旅途上,成为自己的太阳。3.大模型应用
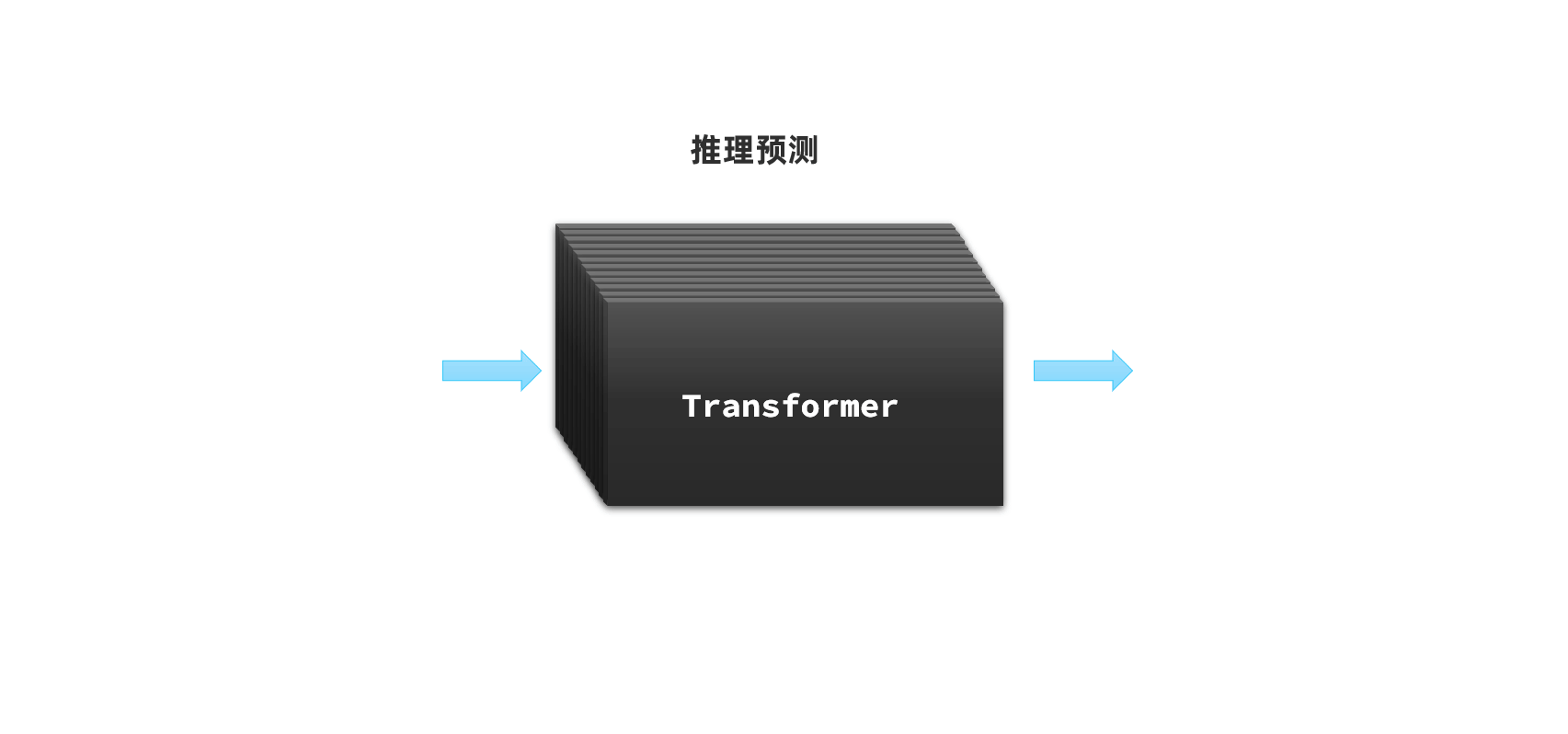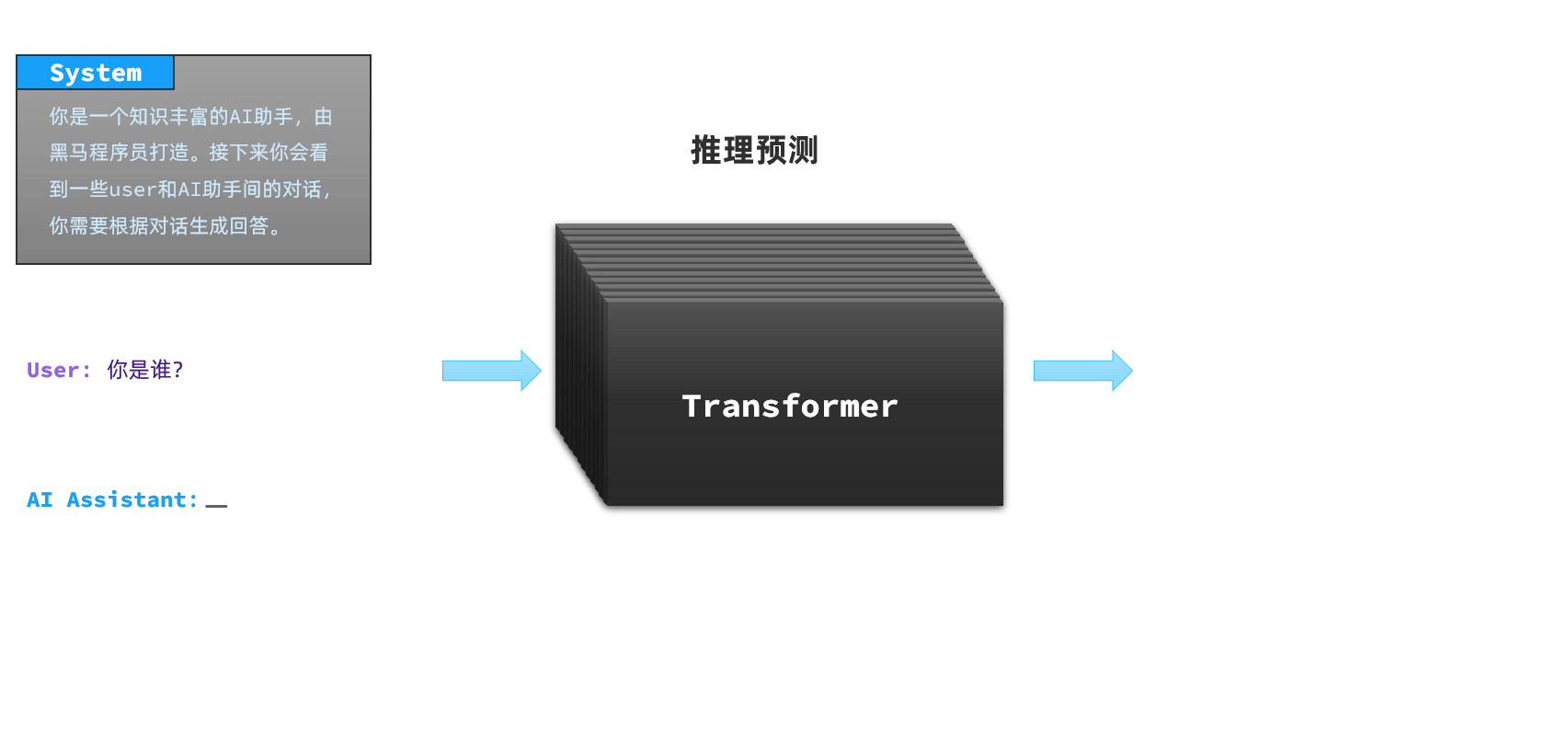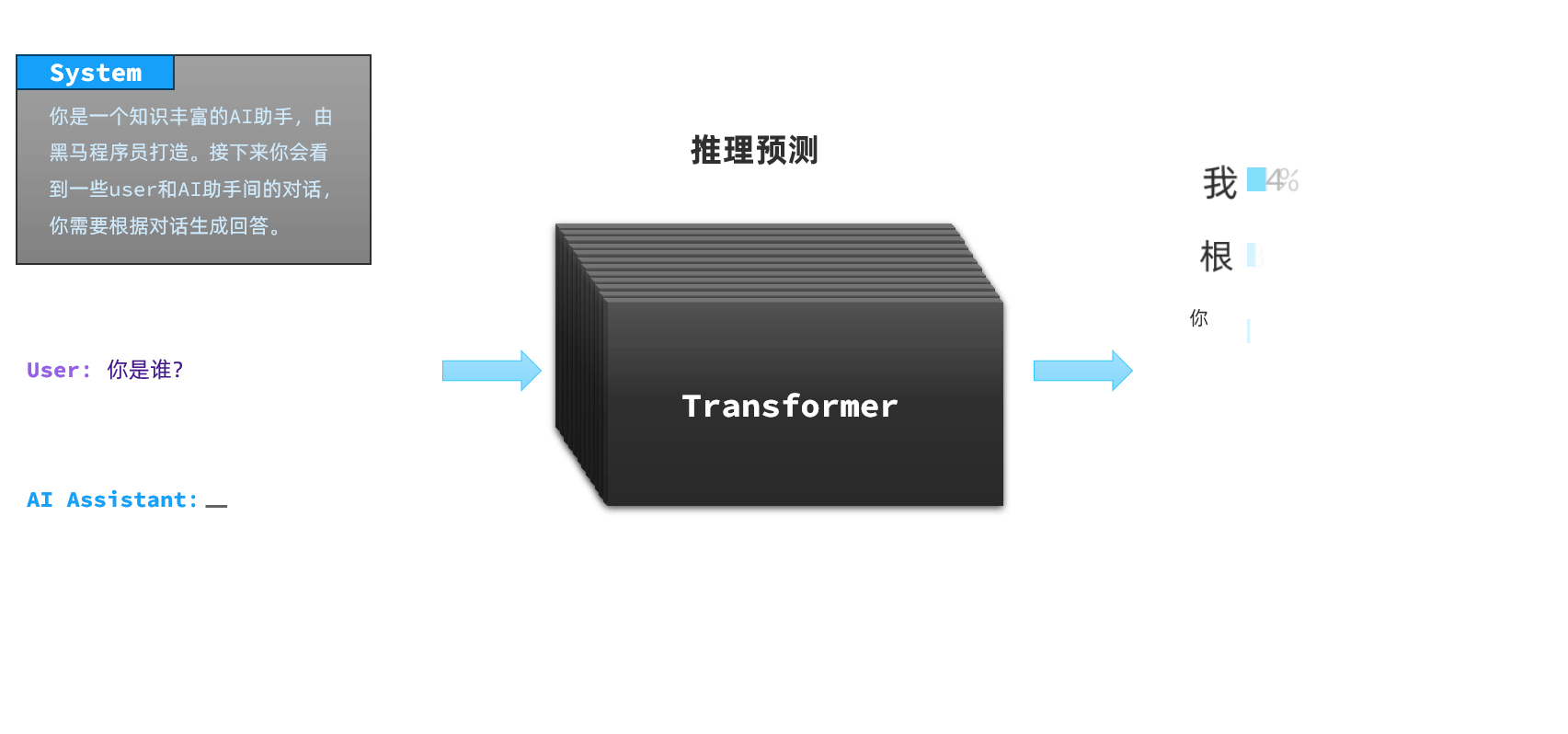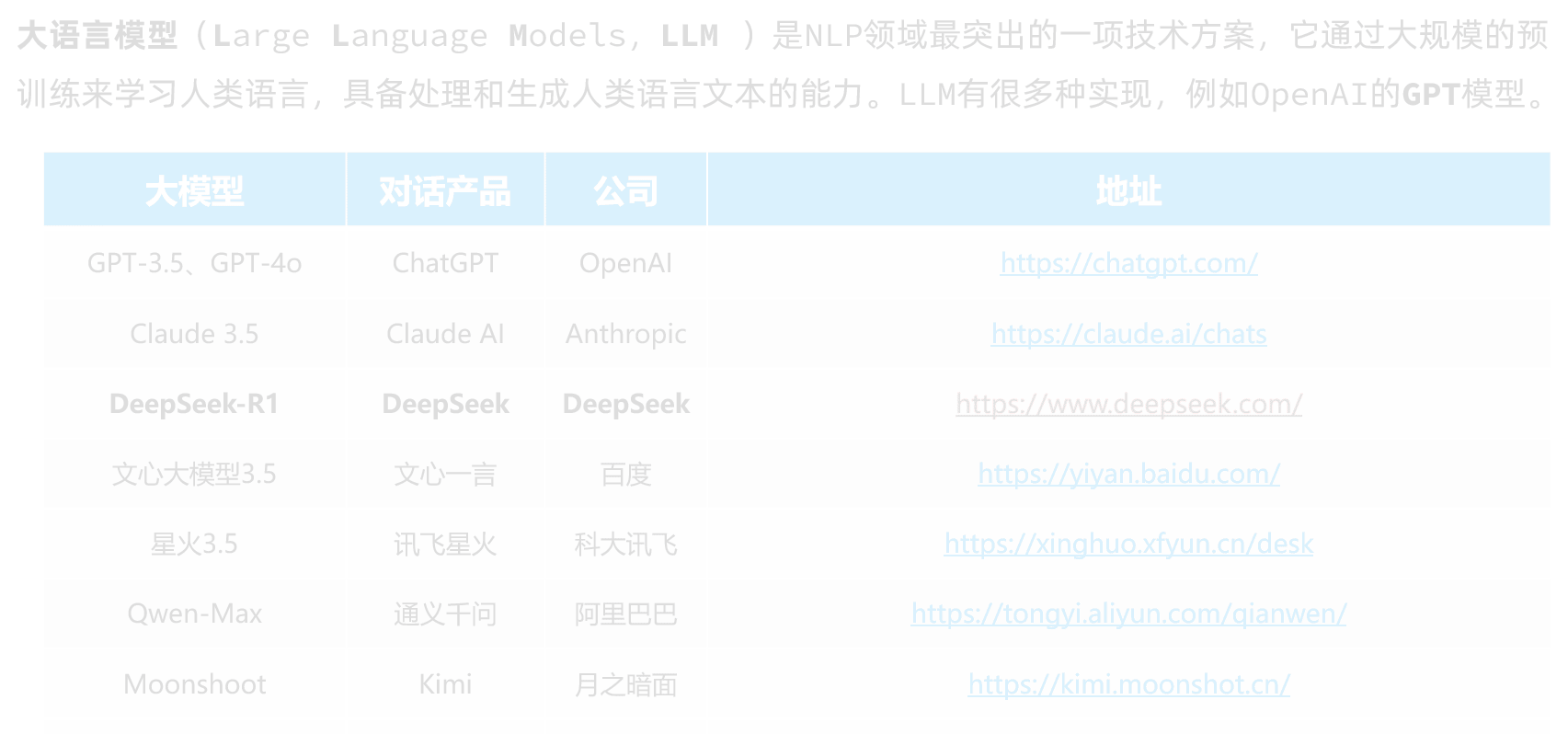
一些大模型对话产品及其对应的模型关系如下:
| 大模型 | 对话产品 | 公司 | 地址 |
|---|---|---|---|
| GPT-3.5、GPT-4o | ChatGPT | OpenAI | https://chatgpt.com/ |
| Claude 3.5 | Claude AI | Anthropic | https://claude.ai/chats |
| DeepSeek-R1 | DeepSeek | 深度求索 | https://www.deepseek.com/ |
| 文心大模型3.5 | 文心一言 | 百度 | https://yiyan.baidu.com/ |
| 星火3.5 | 讯飞星火 | 科大讯飞 | https://xinghuo.xfyun.cn/desk |
| Qwen-Max | 通义千问 | 阿里巴巴 | https://tongyi.aliyun.com/qianwen/ |
| Moonshoot | Kimi | 月之暗面 | https://kimi.moonshot.cn/ |
| Yi-Large | 零一万物 | 零一万物 | https://platform.lingyiwanwu.com/ |
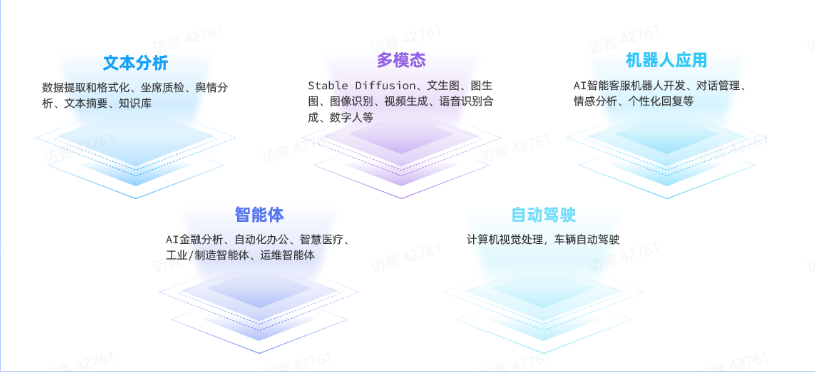
| 除了AI对话应用之外,大模型还可以开发很多其他AI应用,常见领域包括: |
4.大模型应用开发技术框架
4.1.技术架构
目前,大模型应用开发技术架构主要有四种:
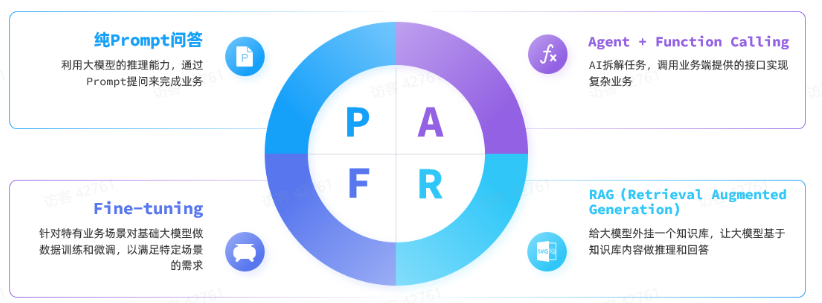
4.1.1.纯Prompt模式
不断雕琢提示词,使大模型给出最理想答案,这个过程就叫提示词工程。
很多简单AI应用,仅仅靠一段足够好的提示词就能实现,这就是纯Prompot模式。
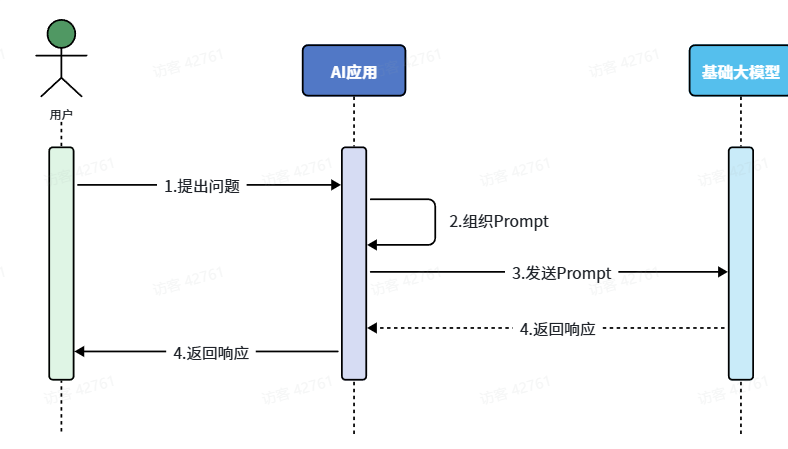
流程图:
4.1.2.FunctionCalling
大模型可以理解自然语言,但无法直接操作数据库,执行严格的业务逻辑,这个时候就能整合传统应用于大模型的能力。
分为以下步骤:
我们可以把传统应用中的部分功能封装成一个个函数(Function)。
然后在提示词中描述用户的需求,并且描述清楚每个函数的作用,要求AI理解用户意图,判断什么时候需要调用哪个函数,并且将任务拆解为多个步骤(Agent)。
当AI执行到某一步,需要调用某个函数时,会返回要调用的函数名称、函数需要的参数信息。
传统应用接收到这些数据以后,就可以调用本地函数。再把函数执行结果封装为提示词,再次发送给AI。
以此类推,逐步执行,直到达成最终结果。
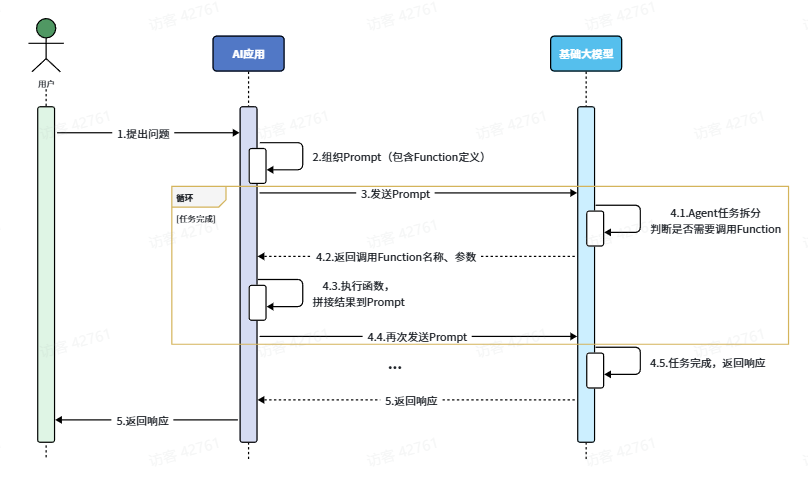
用户提问
↓
AI应用接收用户问题
↓
AI应用把用户问题+可用函数说明一起发给大模型
↓
大模型判断:要不要调用函数、调用哪个函数、参数是什么
↓
大模型返回函数名和参数
↓
AI应用真正执行本地函数/查数据库/调接口
↓
AI应用把函数执行结果再发给大模型
↓
大模型根据结果组织最终回答
↓
AI应用把回答展示给用户4.1.3.RAG
RAG(Retrieval-Augmented Generation)叫做检索增强生成。就是把信息检索技术跟大模型结合的方案。
大模型缺陷:
- 时效性差:大模型训练比较耗时,其训练数据都是旧数据,无法实时更新
- 缺少专业领域知识:大模型训练数据都是采集的通用数据,缺少专业数据
大模型上下文大小有限制,RAG技术来解决这一问题。
RAG分为两个模块:
检索模块(Retrieval):负责存储和检索拓展的知识库
- 文本拆分:将文本按照某种规则拆分为很多片段
- 文本嵌入(Embedding):根据文本片段内容,将文本片段归类存储
- 文本检索:根据用户提问的问题,找出最相关的文本片段
生成模块(Generation):
- 组合提示词:将检索到的片段与用户提问组织成提示词,形成更丰富的上下文信息
- 生成结果:调用生成式模型(例如DeepSeek)根据提示词,生成更准确的回答
由于每次都是从向量库找出与用户问题相关的数据,而不是整个知识库,所以上下文不会超过大模型限制,同时又保证了大模型问题是基于知识库中的内容。
流程图:
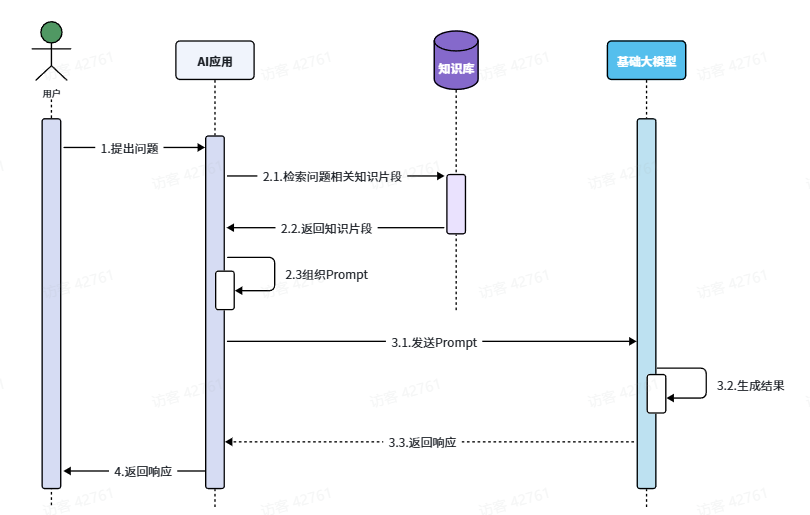
用户提出问题
↓
AI应用接收用户问题
↓
AI应用根据用户问题去知识库检索相关内容
↓
知识库返回与问题相关的知识片段
↓
AI应用把“用户问题+检索到的知识片段”组织成Prompt
↓
AI应用把整理好的Prompt发送给基础大模型
↓
基础大模型根据Prompt中的知识片段生成回答
↓
基础大模型把生成结果返回给AI应用
↓
AI应用把最终回答展示给用户4.1.4.Fine-tuning
Fine-tuning就是模型微调,就是在预训练大模型(比如DeepSeek、Qwen)的基础上,通过企业自己的数据做进一步的训练,使大模型的回答更符合自己企业的业务需求。这个过程通常需要在模型的参数上进行细微的修改,以达到最佳的性能表现。
在进行微调时,通常会保留模型的大部分结构和参数,只对其中的一小部分进行调整。这样做的好处是可以利用预训练模型已经学习到的知识,同时减少了训练时间和计算资源的消耗。微调的过程包括以下几个关键步骤:
- 选择合适的预训练模型:根据任务的需求,选择一个已经在大量数据上进行过预训练的模型,如Qwen-2.5。
- 准备特定领域的数据集:收集和准备与任务相关的数据集,这些数据将用于微调模型。
- 设置超参数:调整学习率、批次大小、训练轮次等超参数,以确保模型能够有效学习新任务的特征。
- 训练和优化:使用特定任务的数据对模型进行训练,通过前向传播、损失计算、反向传播和权重更新等步骤,不断优化模型的性能。
模型微调虽然更加灵活、强大,但是也存在一些问题:
- 需要大量的计算资源
- 调参复杂性高
- 过拟合风险
总之,Fine-tuning成本较高,难度较大,并不适合大多数企业。而且前面三种技术方案已经能够解决常见问题了。
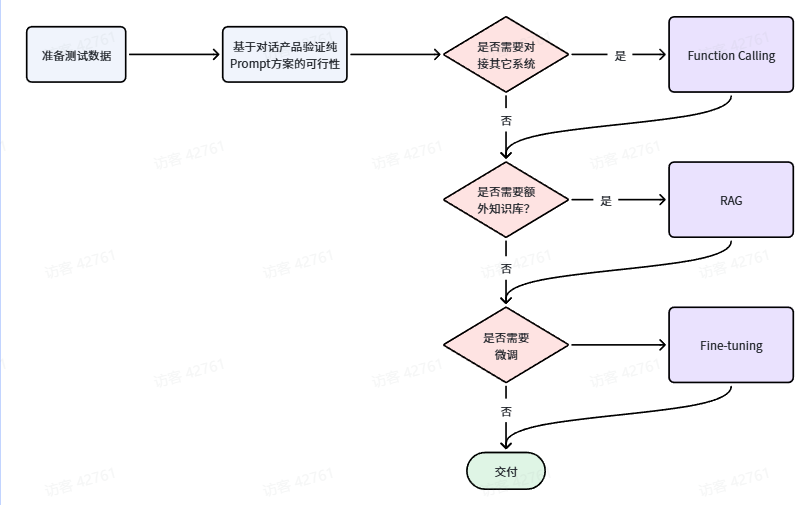
4.2.技术选型
从开发成本由低到高,四种方案排序:
Prompt < Function Calling < RAG < Fine-tuning 所以我们在选择技术时通常也应该遵循"在达成目标效果的前提下,尽量降低开发成本"这一首要原则。然后可以参考以下流程来思考: