Jedis客户端
在Redis官网中提供了各种语言的客户端,地址:https://Redis.io/docs/clients/
其中Java客户端也包含很多
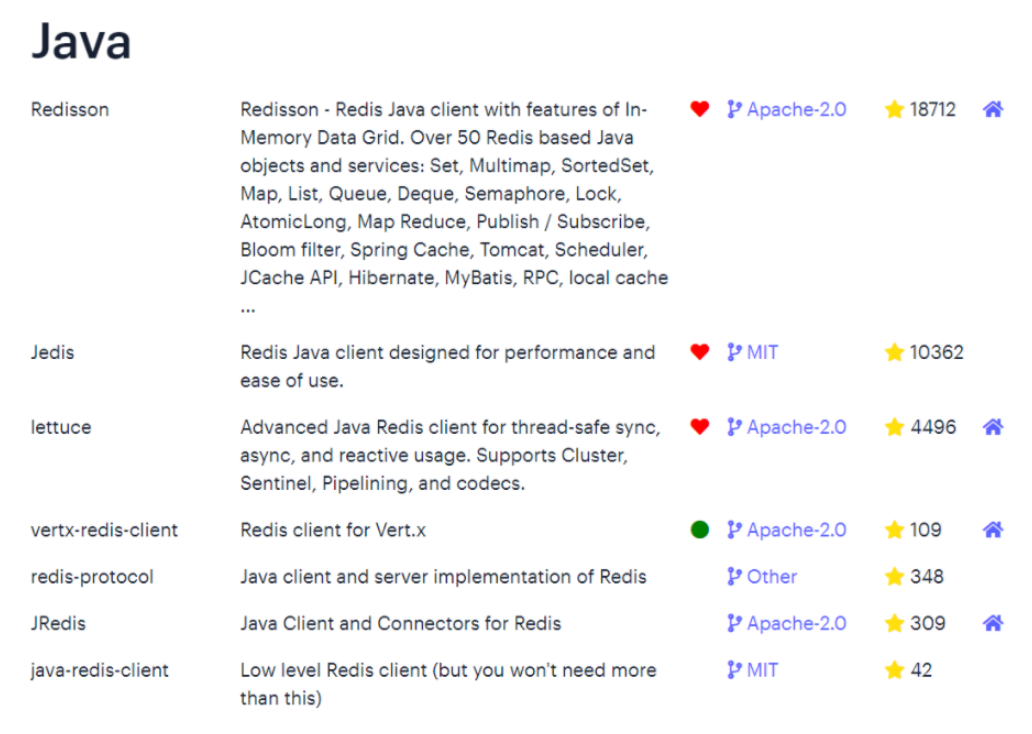
标记为♥的就是Redis官方推荐使用的java客户端,包括:
- Jedis:以Redis命令作为方法名称,学习成本低,简单实用但是Jedis实例是线程不安全的,多线程环境下需要用连接池为每一个线程创建独立的Jedis连接。
- lettuce:是基于
Netty实现的,支持同步、异步和响应式编程方式,并且是线程安全的。支持Redis的哨兵模式、集群模式和管道模式。 - Redisson:是在Redis基础上实现了分布式、可伸缩的Java数据结构集合,例如Map、Queue等,而且支持跨进程的同步机制:Lock、Semaphore等待,比较适合用来实现特殊的功能需求。(后续分布式锁章节来学习Redisson)
Jedis和Lettuce:这两个主要是提供了Redis命令对应的API,方便我们操作Redis,而SpringDataRedis又对这两种做了抽象和封装,因此我们后期会直接以SpringDataRedis来学习。
快速入门
1.引入依赖(官网上复制,有依赖对应的版本说明)
<!-- jedis -->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>5.0.0</version>
</dependency>
<!-- 单元测试 -->
<dependency>
<groupId>org.junit.jupiter</groupId>
<artifactId>junit-jupiter</artifactId>
<version>5.7.0</version>
<scope>test</scope>
</dependency>2.建立连接
新建一个单元测试类,内容如下:
private Jedis jedis;
/**
* 执行setUp相关业务逻辑。
*
* 作用:
* 1.建立连接;
* 2.设置密码;
* 3.选择仓库;
*
* @return无返回值
*/
@BeforeEach
void setUp() {
// 建立连接
jedis = new Jedis("192.168.8.100", 6379);
// 设置密码
jedis.auth("123321");
// 选择仓库
jedis.select(0);
}3.测试
/**
* 执行testString相关业务逻辑。
*
* 作用:
* 1.存入数据;
* 2.获取数据;
*
* @return无返回值
*/
@Test
void testString() {
// 存入数据
String result = jedis.set("name", "Aizen");
System.out.println("result = " + result);
// 获取数据
String name = jedis.get("name");
System.out.println("name = " + name);
}
/**
* 执行testHash相关业务逻辑。
*
* 作用:
* 1.插入hash数据;
* 2.获取hash数据;
*
* @return无返回值
*/
@Test
void testHash() {
// 插入hash数据
jedis.hset("user:1", "name", "Jack");
jedis.hset("user:1", "age", "21");
// 获取hash数据
Map<String, String> map = jedis.hgetAll("user:1");
System.out.println(map);
}4.释放资源
/**
* 执行tearDown相关业务逻辑。
*
* 作用:
* 1.关闭连接;
*
* @return无返回值
*/
@AfterEach
void tearDown() {
// 关闭连接
if (jedis != null) {
jedis.close();
}
}Jedis连接池(已过时,跳过)
Jedis本身是线程不安全的,并且频繁的创建和销毁连接会有性能损耗,因此我们推荐大家使用Jedis连接池代替Jedis的直连方式
有关池化思想,并不仅仅是这里会使用,很多地方都有,比如说我们的数据库连接池,比如我们tomcat中的线程池,这些都是池化思想的体现。
/**
* Jedis连接池
*/
public class JedisConnectionFactory {
private static final JedisPool jedisPool;
static {
// 配置连接池
JedisPoolConfig poolConfig = new JedisPoolConfig();
poolConfig.setMaxTotal(8); // 最大连接数
poolConfig.setMaxIdle(8); // 最大空闲连接数
poolConfig.setMinIdle(0); // 最小空闲连接,如果一直没有被访问,资源就会释放
poolConfig.setMaxWait(Duration.ofMillis(1000)); // 等待时长,当连接池里没有连接可用,需要等待多长时间,默认为-1一直等
// 创建连接池对象
jedisPool = new JedisPool(poolConfig, "192.168.8.100", 6379, 1000, "123321");
}
/**
* 从连接池获取Jedis连接。
*
* @return处理结果
*/
public static Jedis getJedis() {
return jedisPool.getResource();
}
}- 改造原始代码
/**
* 执行setUp相关业务逻辑。
*
* 作用:
* 1.建立连接;
* 2.jedis=newJedis("192.168.8.100",6379);
* 3.设置密码;
* 4.选择仓库;
*
* @return无返回值
*/
@BeforeEach
void setUp() {
// 建立连接
//jedis = new Jedis("192.168.8.100", 6379);
jedis = JedisConnectionFactory.getJedis();
// 设置密码
jedis.auth("123321");
// 选择仓库
jedis.select(0);
}
/**
* 执行tearDown相关业务逻辑。
*
* 作用:
* 1.关闭连接;
* 2.Jedis底层的close方法;
*
* @return无返回值
*/
@AfterEach
void tearDown() {
// 关闭连接
if (jedis != null) {
jedis.close();
}
}
// Jedis底层的close方法
/**
* 释放资源。
*
* @return无返回值
*/
@Override
public void close() {
if (dataSource != null) {
Pool<Jedis> pool = this.dataSource;
this.dataSource = null;
if (isBroken()) {
pool.returnBrokenResource(this);
} else {
pool.returnResource(this);
}
} else {
connection.close();
}
}代码说明:
- 1) JedisConnectionFacotry:工厂设计模式,通过工厂来获得连接池中的Jedis对象,而不用直接去new对象,降低耦合。
- 2)静态代码块:随着类的加载而加载,确保只能执行一次,我们在加载当前工厂类的时候,就可以执行static的操作完成对连接池的初始化。
- 3)使用了连接池创建后,当关闭连接并不是释放资源,而是将Jedis资源归还给连接池。
SpringDataRedis
SpringData是Spring中数据操作的模块,包含对各种数据库的集成,其中对Redis的集成模块就叫做SpringDataRedis,官网地址:https://spring.io/projects/spring-data-Redis
- 提供了对不同Redis客户端的整合(Lettuce和Jedis)
- 提供了RedisTemplate统一API来操作Redis
- 支持Redis的发布订阅模型
- 支持Redis哨兵和Redis集群
- 支持基于Lettuce的响应式编程
- 支持基于JDK.JSON.字符串.Spring对象的数据序列化及反序列化
- 支持基于Redis的JDKCollection实现
SpringDataRedis中提供了RedisTemplate工具类,其中封装了各种对Redis的操作。并且将不同数据类型的操作API封装到了不同的类型中:`

快速入门
SpringBoot已经提供了对SpringDataRedis的支持,使用非常简单。
- 导入pom依赖
<dependencies>
<!-- spring-data-redis -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<!-- commons-pool2连接池 -->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
</dependency>
<!-- Jackson -->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<excludes>
<exclude>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</exclude>
</excludes>
</configuration>
</plugin>
</plugins>
</build>- yaml配置文件
# spring-data-redis
spring:
data:
redis:
host: 192.168.8.100
port: 6379
password: 123321
lettuce:
pool: # lettuce的pool必须手动配置才会生效
max-active: 8 # 最大连接
max-idle: 8 # 最大空闲连接
min-idle: 0 # 最小空闲连接
max-wait: 1000ms # 连接等待时间- 注入RedisTemplate直接使用
@SpringBootTest
class SpringDataRedisTests {
@Autowired
private RedisTemplate<String, Object> redisTemplate; // 注入RedisTemplate
/**
* 执行testString相关业务逻辑。
*
* @return无返回值
*/
@Test
void testString() {
// 写入一条String数据
redisTemplate.opsForValue().set("name", "虎哥");
// 获取String数据
Object name = redisTemplate.opsForValue().get("name");
System.out.println("name = " + name);
}
}自定义序列
RedisTemplate可以接收任意Object作为值写入Redis:
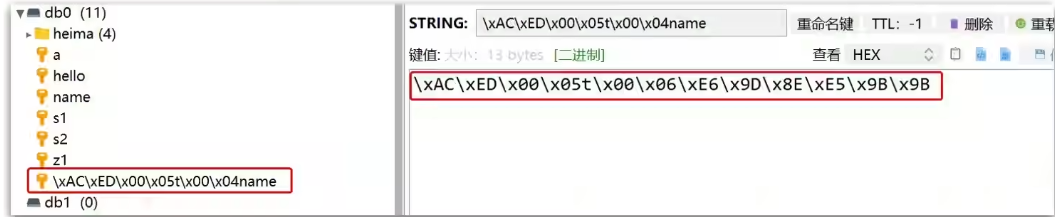
只不过写入前会把Object序列化为字节形式,默认是采用JDK序列化(JdkSerializationRedisSerializer),JDK序列化底层使用的是ObjectOutputStream将Java对象转为字节后写入Redis,得到的结果是这样的:
缺点:
- 可读性差
- 内存占用较大
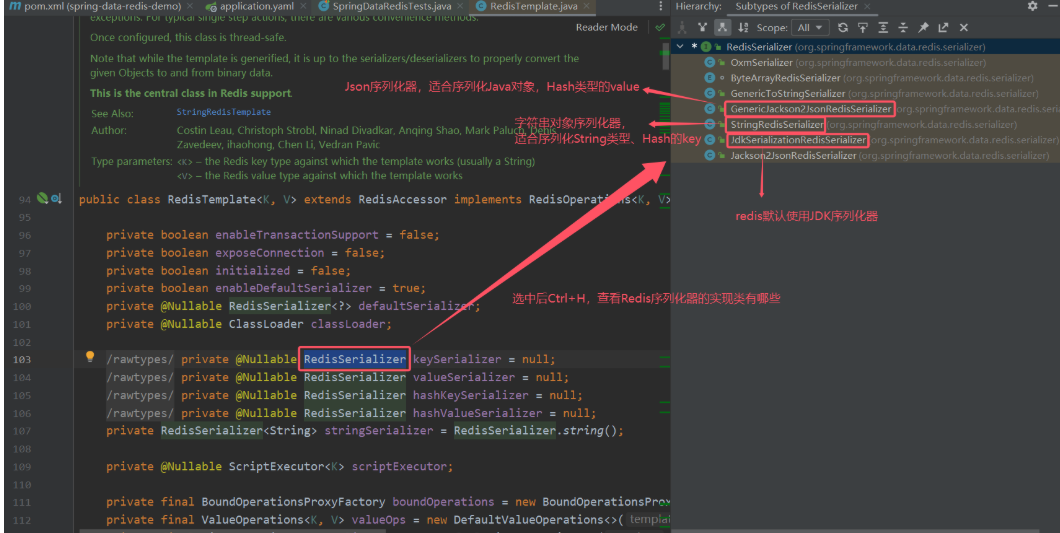
我们可以创建一个RedisConfig配置类,自定义RedisTemplate的序列化方式。
@Configuration
public class RedisConfig {
/**
* 配置RedisTemplate序列化方式。
*
* 作用:
* 1.创建RedisTemplate对象;
* 2.设置连接工厂;
* 3.创建JSON序列化工具;
* 4.设置Value和HashValue的序列化方式为:json;
*
* @param connectionFactory connectionFactory参数
* @return处理结果
*/
@Bean
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory connectionFactory) {
// 创建RedisTemplate对象
RedisTemplate<String, Object> redisTemplate = new RedisTemplate<>();
// 设置连接工厂
redisTemplate.setConnectionFactory(connectionFactory);
// 创建JSON序列化工具
GenericJackson2JsonRedisSerializer jsonRedisSerializer = new GenericJackson2JsonRedisSerializer();
// 设置Key和HashKey的序列化:String
redisTemplate.setKeySerializer(RedisSerializer.string());
redisTemplate.setHashKeySerializer(RedisSerializer.string());
// 设置Value和HashValue的序列化方式为:json
redisTemplate.setValueSerializer(jsonRedisSerializer);
redisTemplate.setHashValueSerializer(jsonRedisSerializer);
return redisTemplate;
}
}这里采用了JSON序列化来代替默认的JDK序列化方式。最终结果如图
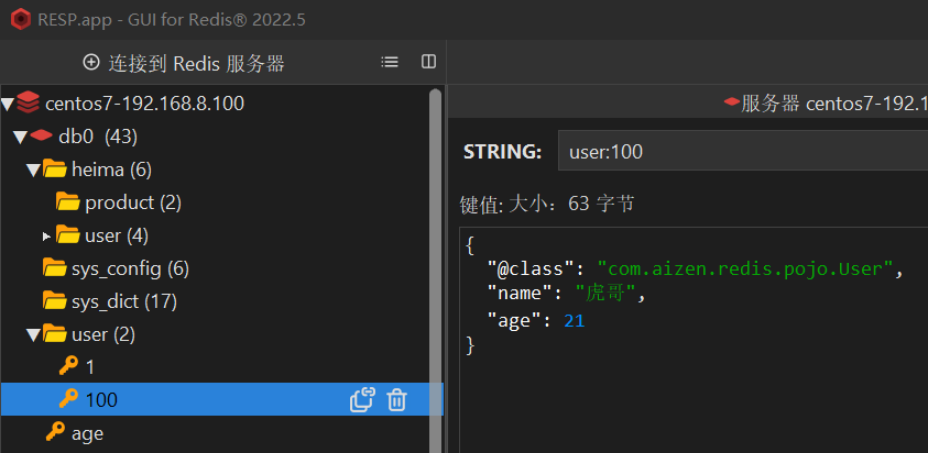
整体可读性有了很大提升,并且能将Java对象自动的序列化为JSON字符串,并且查询时能自动把JSON反序列化为Java对象。不过,其中记录了序列化时对应的class全类名,目的是为了查询时实现自动反序列化。这会带来额外的内存开销。
StringRedisTemplate
尽管JSON的序列化方式可以满足我们的需求,但依然存在一些问题,如图:
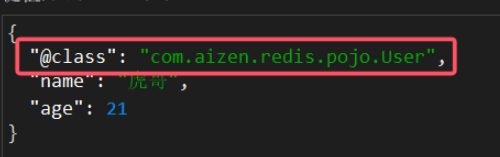
为了在反序列化时知道对象的类型,JSON序列化器会将类的class类型写入json结果中,存入Redis,会带来额外的内存开销。
为了减少内存的消耗,我们可以采用手动序列化的方式,换句话说,就是不借助默认的序列化器,而是我们自己来控制序列化的动作,同时,我们只采用String的序列化器,这样在存储value时,我们就不需要在内存中就不用多存储数据,从而节约我们的内存空间。 
这种用法比较普遍,因此SpringDataRedis就提供了RedisTemplate的子类:StringRedisTemplate,它的key和value的序列化方式默认就是String方式。
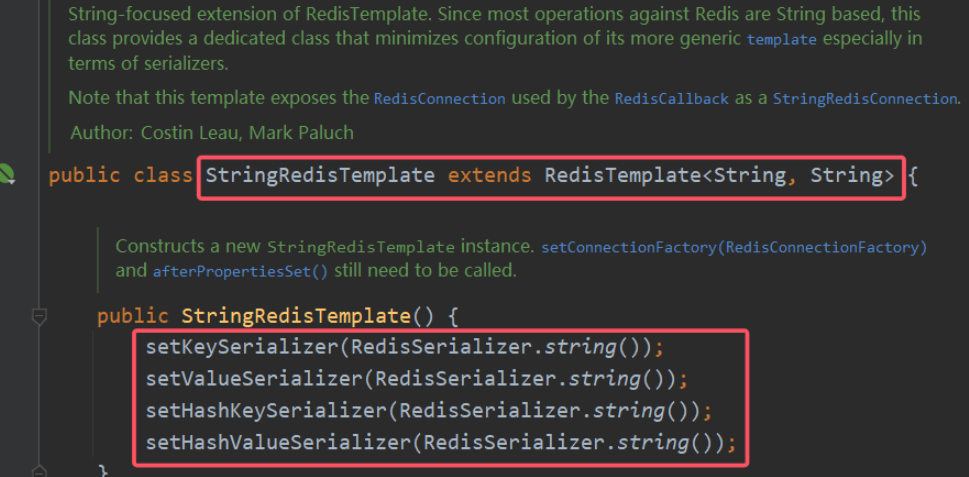
省去了我们编写RedisConfig配置类自定义RedisTemplate的序列化方式的步骤,而是直接使用:
@SpringBootTest
class SpringRedisTemplateTests {
@Autowired
private StringRedisTemplate stringRedisTemplate; // 注入StringRedisTemplate
/**
* 执行testString相关业务逻辑。
*
* @return无返回值
*/
@Test
void testString() {
// 写入一条String数据
stringRedisTemplate.opsForValue().set("name", "虎哥");
// 获取String数据
Object name = stringRedisTemplate.opsForValue().get("name");
System.out.println("name = " + name);
}
private static final ObjectMapper mapper = new ObjectMapper();
/**
* 执行testSaveUser相关业务逻辑。
*
* 作用:
* 1.创建对象;
* 2.手动序列化;
* 3.写入User对象(将Java对象序列化为json);
* 4.获取数据(将json反序列化为Java对象);
* 5.手动反序列化;
*
* @return无返回值
*/
@Test
void testSaveUser() throws JsonProcessingException {
// 创建对象
User u = new User("虎哥", 21);
// 手动序列化
String json = mapper.writeValueAsString(u);
// 写入User对象(将Java对象序列化为json)
stringRedisTemplate.opsForValue().set("user:200", json);
// 获取数据(将json反序列化为Java对象)
String jsonUserStr = stringRedisTemplate.opsForValue().get("user:200");
// 手动反序列化
User user = mapper.readValue(jsonUserStr, User.class);
System.out.println("user = " + user);
}
}此时再看存储的数class数据已经不存在,节约了内存空间。
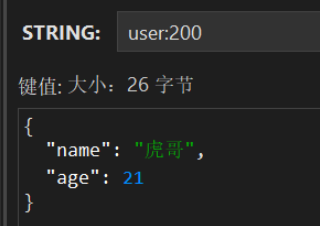
- Hash结构的操作
/**
* 执行testHash相关业务逻辑。
*
* @return无返回值
*/
@Test
void testHash() {
stringRedisTemplate.opsForHash().put("user:300", "name", "虎哥");
stringRedisTemplate.opsForHash().put("user:300", "age", "21");
String name = (String) stringRedisTemplate.opsForHash().get("user:300", "name");
System.out.println("name = " + name);
Map<Object, Object> entries = stringRedisTemplate.opsForHash().entries("user:300");
System.out.println("entries = " + entries);
}
总结:RedisTemplate的两种序列化实践方案 方案一: 自定义RedisTemplate 修改RedisTemplate的序列化器为GenericJackson2JsonRedisSerializer 方案二: 使用StringRedisTemplate 写入Redis时,手动把对象序列化为JSON 读取Redis时,手动把读取到的JSON反序列化为对象