1.SpringAI入门
SpringAI整合了全球大多数大模型,而且对于大模型开发的三种技术架构都有比较好的封装和支持,开发起来非常方便。
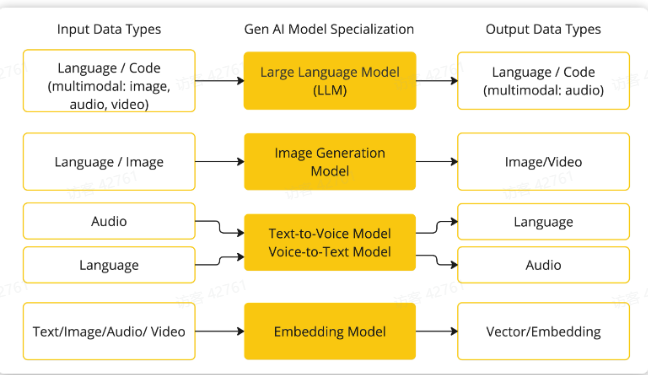
不同模型能够接受的输入类型、输出类型不一定相同。SpringAI根据模型的输入和输出类型不同对模型进行了分类:
1.1. 快速入门
1.1.1.创建工程
创建一个新的SpringBoot工程,JDK版本是17:
原始pom.xml如下:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.5.3</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.itheima</groupId>
<artifactId>spring-ai-demo</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>spring-ai-demo</name>
<description>spring-ai-demo</description>
<url/>
<licenses>
<license/>
</licenses>
<developers>
<developer/>
</developers>
<scm>
<connection/>
<developerConnection/>
<tag/>
<url/>
</scm>
<properties>
<java.version>17</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>1.1.2.引入依赖
SpringAI完全失陪了SpringBoot的自动装配功能,而且给不同大模型提供了不同starter。
这里以Ollama为例。
首先,在项目pom.xml中添加spring-ai的版本信息
<spring-ai.version>1.0.0</spring-ai.version>然后,添加spring-ai的依赖管理项:
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-bom</artifactId>
<version>${spring-ai.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>最后,引入spring-ai-dpeepseek的依赖:
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-deepseek</artifactId>
</dependency>最后为了方便开发,在引入一个Lombok依赖:
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.22</version>
</dependency>1.1.3.配置模型信息
以ollama为例,在application.yaml添加如下内容:
spring:
application:
name: heima-ai
ai:
ollama:
base-url: http://localhost:11434
chat:
model: qwen2.5:3b1.1.4.ChatClient
ChatClient中封装了与AI大模型对话的各种API,同时支持同步式或响应式交互。
不过在使用之前,我们需要先声明一个ChatClient。
在config包下新建一个CommonConfiguration类:
完整代码如下:
@Configuration
public class CommonConfiguration {
//参数中的model就是使用的模型
@Bean
public ChatClient chatClient(OllamaChatModel model, ChatMemory chatMemory){
return ChatClient
.builder(model) //创建ChatClient工厂
.build(); //构建ChatClient实例
}
}ChatClient.builder:会得到一个ChatClient.Builder工厂对象,利用它可以自由选择模型、添加各种自定义配置。OllamaChatModel:引入了ollama的starter,这里就可以自动注入模型对象。
1.1.5.同步调用
我们定义一个Controller,在其中接受用户发送的提示词,然后把提示词发送给大模型,交给大模型处理,拿到结果后返回。
代码如下:
@RequestMapping("/ai")
@RestController
@RequiredArgsConstructor
public class ChatController {
private final ChatClient chatClient;
@RequestMapping("/chat")
public String chat(@RequestParam(defaultValue = "你好~") String prompt) {
return chatClient
.prompt(prompt) //传入用户提示词
.call() //同步请求,会等待AI全部输出完才返回结果
.content(); //返回响应内容
}
}基于call()方法的调用属于同步调用,需要大模型返回所有响应结果后,才能返回给前端。需要等待较长时间。
启动项目,在浏览器中访问http://localhost:8080/ai/chat?prompt=你好
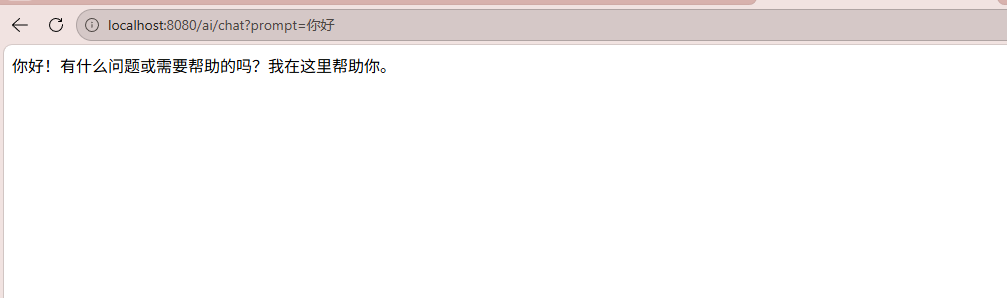
1.1.6.流式调用
同步调用需要等待很长时间页面才能看到结果,用户体验不好。为了解决这个问题,我们可以改进调用方式为流式调用。
在SpringAI中使用了WebFlux技术实现流式调用。
修改刚才ChatController中的chat方法:
@RequestMapping(value = "/chat", produces = "text/html;charset=UTF-8") //告诉浏览器编码格式是utf-8
public Flux<String> chat(@RequestParam(defaultValue = "讲个笑话") String prompt) {
return chatClient
.prompt(prompt)
.stream()
.content();
}1.1.7.System设定
如果我们希望AI按照我们给的设定工作,就需要给他设置System背景信息。
在SpringAI中,设置System信息非常方便,不需要再每次发送时封装到Message,而是创建ChatClient时指定即可。
我们修改SpringAIConfiguration中的代码,给ChatClient设定默认的System信息:
@Bean
public ChatClient chatClient(OllamaChatModel model, ChatMemory chatMemory){
return ChatClient
.builder(model)
.defaultSystem("你是可爱又迷人的反派角色,火箭队的武藏")
.build();
}
1.2.推理模型
- deepseek-reasoner:推理模型,目前版本是DeepSeek-R1-0528
- deepseek-chat:普通模型,目前版本是DeepSeek-V3-0324
SpringAI中默认采用的是deepseek-chat模型,所以看不到推理过程。
1.2.1.修改模型
有两种办法可以修改模型:
- 全局配置:在application.yml配置文件中修改模型,作用域全局
- 局部配置:在
ChatClient中修改模型,作用域局部
application.yml的配置刚才已经说过,接下来我们以ChatClient的局部配置为例来介绍。
修改SpringAIConfiguration中的ChatClient的配置:
package com.itheima.ai.config;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.prompt.ChatOptions;
import org.springframework.ai.deepseek.DeepSeekChatModel;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class SpringAIConfiguration {
@Bean
public ChatClient chatClient(DeepSeekChatModel chatModel){
return ChatClient.builder(chatModel)
.defaultOptions(ChatOptions.builder().model("deepseek-reasoner").build())
.defaultSystem("你是可爱又迷人的反派角色,火箭队的武藏。回答中可以用表情~")
.build();
}
}1.2.2.输出推理过程
重启测试后,会发现输出的结果依然是没有思考推理过程。怎么回事?
这是因为DeepSeek返回的思考内容与普通内容不是在一起的,而是分为两个字段返回:
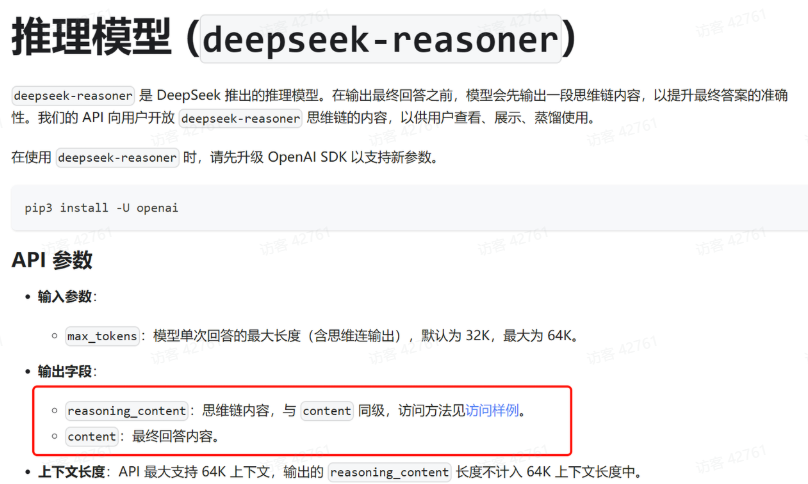
在SpringAI中,普通模型返回的结果都是AssistantMessage类型,而DeepSeek模型返回的结果是DeepSeekAssistantMessage类型,官方给出的解决方案是这样的:
public void deepSeekReasonerExample() {
DeepSeekChatOptions promptOptions = DeepSeekChatOptions.builder()
.model(DeepSeekApi.ChatModel.DEEPSEEK_REASONER.getValue())
.build();
Prompt prompt = new Prompt("9.11 and 9.8, which is greater?", promptOptions);
ChatResponse response = chatModel.call(prompt);
// Get the CoT content generated by deepseek-reasoner, only available when using deepseek-reasoner model
DeepSeekAssistantMessage deepSeekAssistantMessage = (DeepSeekAssistantMessage) response.getResult().getOutput();
String reasoningContent = deepSeekAssistantMessage.getReasoningContent();
String text = deepSeekAssistantMessage.getText();
}所以,我们可以模仿这种方式。修改ChatController中的代码:
package com.itheima.ai.controller;
import lombok.RequiredArgsConstructor;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.model.ChatResponse;
import org.springframework.ai.deepseek.DeepSeekAssistantMessage;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import reactor.core.publisher.Flux;
@RequiredArgsConstructor
@RestController
@RequestMapping("/ai")
public class ChatController {
private final ChatClient chatClient;
@RequestMapping(value = "/chat", produces = "text/html;charset=UTF-8")
public Flux<String> chat(@RequestParam(defaultValue = "讲个笑话") String prompt) {
return chatClient
.prompt(prompt)
.stream()
.chatResponse()
.mapNotNull(this::handleReasonerMessage); // 处理推理结果
}
private String handleReasonerMessage(ChatResponse response) {
// 获取消息,转为DeepSeekAssistantMessage
DeepSeekAssistantMessage message = (DeepSeekAssistantMessage) response.getResult().getOutput();
// 获取推理结果
String reasoningContent = message.getReasoningContent();
if (reasoningContent != null && !reasoningContent.isBlank()) {
// 如果推理结果存在,则将其包裹上<think></think>标签,方便前端处理
return "<think>" + reasoningContent + "</think>";
}
// 没有推理结果,直接返回文本
return message.getText();
}
}1.2.3.ollama推理输出
本地使用deepseek-r1:1.5b,使用.enableThinking()让模型开启思考过程,DeepSeek R1 本身支持推理,但 Spring AI 发请求时最好明确加上 think=true。不加的话,有些 Ollama 版本/模型配置可能只返回最终答案,不返回 thinking 字段。 具体代码如下:
@RequestMapping(value = "/chat", produces = "text/html;charset=UTF-8")
public Flux<String> chat(@RequestParam(defaultValue = "讲个笑话") String prompt) {
return chatClient
.prompt(prompt)
.options(OllamaChatOptions.builder()
.model("deepseek-r1:1.5b").enableThinking().build())
.stream()
.chatResponse() //获取全部chatresponse响应对象,而不是文本内容
.flatMap(response->{
String thinking = response.getResult().getMetadata().get("thinking"); //Ollama 的推理内容不是放在正文里,而是放在响应的metadata里
String answer = response.getResult().getOutput().getText();
if (thinking != null && !thinking.isBlank()) {
return Flux.just("\n" + thinking);
}
if (answer != null && !answer.isBlank()) {
return Flux.just(answer);
}
return Flux.empty();
});
}1.3.日志功能
1.3.1.Advisor
SpringAI基于AOP机制实现与大模型对话过程的增强、拦截修改等功能。所有的增强通知都需要实现Advisor接口。
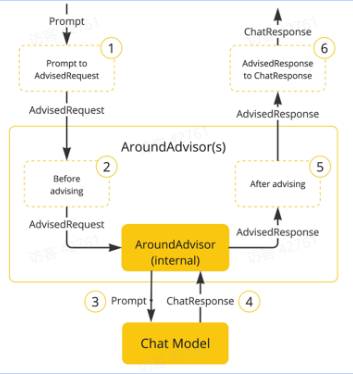
Spring提供了一些Advisor的默认实现,来实现一些基本的增强功能:

- SimpleLoggerAdvisor:日志记录的Advisor
- MessageChatMemoryAdvisor:会话记忆的Advisor
- QuestionAnswerAdvisor:实现RAG的Advisor
当然,我们也可以自定义Advisor,具体可以参考: [SpringAI](Advisors API :: Spring AI Reference)
1.3.2.添加日志Advisor
首先需要修改SpringAIConfiguration,给ChatClient添加日志Advisor:
@Bean
public ChatClient chatClient(OllamaChatModel chatModel){
return ChatClient.builder(chatModel)
.defaultOptions(OllamaChatOptions.builder()
.model("deepseek-r1:1.5b").enableThinking().build())
.defaultSystem("你是可爱又迷人的反派角色,火箭队的武藏。回答中可以用表情~")
.defaultAdvisors(
SimpleLoggerAdvisor.builder().build() // 添加日志记录advisor
)
.build();
}1.3.3.修改日志级别
接下来,再application.yaml中添加日志配置,更新日志级别:
logging:
level:
org.springframework.ai: debug #AI对话的日志级别
com.example.ai: debug #本项目的日志级别重启项目,再次聊天就能看到AI对话的日志信息了。
1.4.对接前端
Nginx运行
# 启动Nginx
start nginx.exe
# 停止
nginx.exe -s stop启动后,访问http://localhost:5173即可看到页面:
1.5.会话记忆
大语言模型是无状态的,意味着他们不会保留以前交互的信息。如果想让大模型知道之前聊了什么,就需要在每次与大模型交互时携带会话的历史信息,也就是会话的上下文。
我们可以把用户与LLM所有会话历史保存下来,不过LLM的上下文是有限制的,因此,当历史会话过多时,没有办法把所有历史回话都拼接到上下文中,也就是说LLM的记忆会受限。
两个概念上的差异:
- 会话历史:会话完整记录,包含用户与LLM之间交互的所有消息。
- 会话记忆:每次会话时携带在上下文中的部分信息。用于让LLM感知聊天的历史。
SpringAI只提供了会话记忆功能(并非会话历史),我们只需要简单配置就能使用了。包含两部分:
ChatMemory:会话记忆管理,管理会话上下文。ChatMemoryRepository:会话记忆存储管理,实现会话记忆的读写操作。
注意: ChatMemory 负责记忆管理和裁剪规则。 ChatMemoryRepository 负责把裁剪后的记忆存起来。
1.5.1.ChatMemory
ChatMemory负责管理会话记忆,也就是决定会话历史中的哪一部分作为会话记忆。其接口声明如下:
package org.springframework.ai.chat.memory;
import java.util.List;
import org.springframework.ai.chat.messages.Message;
import org.springframework.util.Assert;
public interface ChatMemory {
String DEFAULT_CONVERSATION_ID = "default";
String CONVERSATION_ID = "chat_memory_conversation_id";
default void add(String conversationId, Message message) {
Assert.hasText(conversationId, "conversationId cannot be null or empty");
Assert.notNull(message, "message cannot be null");
this.add(conversationId, List.of(message));
}
void add(String conversationId, List<Message> messages);
List<Message> get(String conversationId);
void clear(String conversationId);
}所有的会话记忆都是与conversationId有关联的,也就是会话Id,将来不同会话id的记忆自然是分开管理的。
ChatMemory有一个默认的实现:MessageWindowChatMemory,即固定窗口大小的会话记忆。它会设定一个会话记忆的窗口,并设定该窗口允许的最大值。当消息数超过最大值时,将删除较旧的消息,保留新消息。默认窗口大小为 20。
ChatMemory只负责管理会话记忆,而不是读写记忆。真正读写会话记忆还要靠ChatMemoryRepository来实现。
1.5.2.ChatMemoryRepository
ChatMemoryRepository是SpringAI提供的会话记忆存储接口,强调一下,这个不是会话历史。因为它每次保存会话都会删除旧的会话。
ChatMemoryRepository有很多种实现方式,也就是说你可以用不同的方式来存储会话记忆。例如:
InMemoryChatMemoryRepository:基于内存存储,底层是ConcurrentHashMap,默认方案JdbcChatMemoryRepository:基于JDBC在关系数据库中存储,支持多种数据库CassandraChatMemoryRepository:基于Apache Cassandra 存储消息。
默认方案是InMemoryChatMemoryRepository,也就是把会话记忆存储在内存中,
以JdbcChatMemoryRepository为例,分为四步:
- 引入依赖
依赖如下:
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-chat-memory-repository-jdbc</artifactId>
</dependency>
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
</dependency>- 准备SQL脚本
CREATE TABLE IF NOT EXISTS SPRING_AI_CHAT_MEMORY (
`id` BIGINT(19) NOT NULL AUTO_INCREMENT,
`conversation_id` VARCHAR(36) NOT NULL COLLATE 'utf8mb4_general_ci',
`content` TEXT NOT NULL COLLATE 'utf8mb4_general_ci',
`type` VARCHAR(10) NOT NULL COLLATE 'utf8mb4_general_ci',
`timestamp` TIMESTAMP NOT NULL,
PRIMARY KEY (`id`) USING BTREE,
INDEX `SPRING_AI_CHAT_MEMORY_CONVERSATION_ID_TIMESTAMP_IDX` (`conversation_id`, `timestamp`) USING BTREE,
CONSTRAINT TYPE_CHECK CHECK (type IN ('USER', 'ASSISTANT', 'SYSTEM', 'TOOL'))
);需要将脚本放在项目的resource目录中,例如:
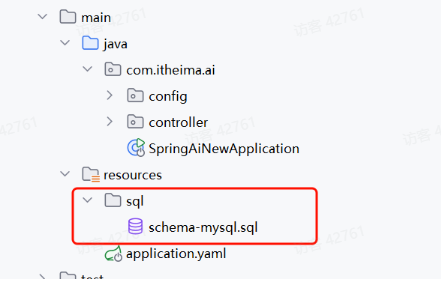
- 配置
在application.yml中添加相关配置:
spring:
application:
name: spring-ai-demo
ai:
deepseek:
api-key: ${DEEPSEEK_API_KEY} # 获取 DeepSeek API Key
chat:
options:
model: deepseek-chat # 模型名称,默认为 deepseek-chat,可以不配
chat:
memory:
repository:
jdbc:
initialize-schema: always # 自动建表
schema: classpath:sql/schema-mysql.sql # 建表脚本
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/spring-ai-demo?serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=utf-8&allowPublicKeyRetrieval=true&useSSL=false
username: root
password: xxx
logging:
level:
com.itheima: debug
org.springframework.ai: debug- 使用 最后,只需要在自定义
ChatMemory时配置即可。修改CommonConfiguration,添加配置:
@Bean
public ChatMemory chatMemory(JdbcChatMemoryRepository chatMemoryRepository) {
return MessageWindowChatMemory.builder()
.chatMemoryRepository(chatMemoryRepository)
.maxMessages(20)
.build();
}1.5.3.添加会话记忆Advisor
有了ChatMemory之后,会话记忆就可以交给Spring管理了。Spring底层还是通过AOP方式来实现的,通过MessageChatMemoryAdvisor拦截请求,把消息写入ChatMemory。
所以,还需要在ChatClient中配置MessageChatMemoryAdvisor
然后添加MessageChatMemoryAdvisor到ChatClient:
@Bean
public ChatClient chatClient(OllamaChatModel chatModel, ChatMemory chatMemory){
return ChatClient.builder(chatModel)
.defaultOptions(OllamaChatOptions.builder()
.model("deepseek-r1:1.5b").enableThinking().build())
.defaultSystem("你是可爱又迷人的反派角色,火箭队的武藏。回答中可以用表情~")
.defaultAdvisors(
SimpleLoggerAdvisor.builder().build(), // 添加日志记录advisor
MessageChatMemoryAdvisor.builder(chatMemory).build() //会话记忆advisor
)
.build();
}1.5.4.添加会话id
ChatMemory的会话记忆管理是基于conversationId的,用conversationId来区分不同的会话。
所以,为了区分不同的会话,我们还需要再发送请求时携带会话id:
@RequestMapping(value = "/chat", produces = "text/html;charset=UTF-8")
public Flux<String> chat(@RequestParam(defaultValue = "讲个笑话") String prompt,
@RequestParam("chatId")String chatId) {
return chatClient
.prompt(prompt)
.advisors(as->as.param(ChatMemory.CONVERSATION_ID,chatId))
.stream()
.chatResponse()
.flatMap(response->{
String thinking = response.getResult().getMetadata().get("thinking");
String answer = response.getResult().getOutput().getText();
if (thinking != null && !thinking.isBlank()) {
return Flux.just("\n" + thinking);
}
if (answer != null && !answer.isBlank()) {
return Flux.just(answer);
}
return Flux.empty();
});
}1.5.5. ChatMemoryRepository分类
Spring AI 里常见的 ChatMemoryRepository 可以按存储方式分成三类:内存版、JDBC 版、Cassandra 版。
1.内存版 InMemoryChatMemoryRepository:数据存在 Java 后端进程内存里。
- 特点:
- 不需要数据库
- 使用最简单
- 后端一重启,记忆全部丢失
- 不能多实例共享
- 适合学习、测试、Demo
- 典型场景:
- 本地练习 Spring AI
- 临时对话上下文
- 不关心服务重启后的记忆
- 生命周期: 后端进程还活着+conversationId相同 = 能继续记住 后端重启 = 全部清空
2.JDBC 版 JdbcChatMemoryRepository:数据存在关系型数据库里,比如 MySQL、PostgreSQL。
- 特点:
- 需要配置 DataSource
- 需要数据库表
- 后端重启后记忆还在
- 多个后端实例可以共享同一个数据库
- 适合普通业务项目 一般需要建表配置:
spring:
ai:
chat:
memory:
repository:
jdbc:
initialize-schema: always
schema: classpath:sql/schema-mysql.sql典型场景:
- 单体项目或普通 Web 项目
- 希望重启后还能保留上下文记忆
- 用 MySQL/PostgreSQL 保存记忆
注意: JDBC 保存的是 ChatMemory 记忆,不等于完整聊天历史。 如果设置了窗口大小,旧消息仍可能被裁剪。
3.Cassandra 版 CassandraChatMemoryRepository:数据存在 Cassandra 这种分布式 NoSQL 数据库里。
特点:
- 适合大规模、高并发、分布式场景
- 可以横向扩展
- 写入能力强
- 部署和维护成本高
- 普通项目一般用不上
典型场景:
- 大规模 AI 聊天系统
- 多节点部署
- 海量 conversationId
- 需要高可用和分布式存储
不适合:
- 本地学习
- 小型项目
- 单机应用
- 普通管理系统
2.会话管理
这里有几个概念我们要区分清楚:
会话记录:用户有几次会话,每次会话是什么,包含:
会话id:也就是conversationId
创建时间:会话创建的时间
标题:可以根据会话内容让AI提取出标题
所属用户:如果存在多用户的话,可以加上用户id信息
... :其它业务相关字段
会话历史:每次会话完整历史记录,包含用户与LLM之间交互的所有消息。有两类:
userMessage:用户提问的消息
assistantMessage:AI返回的消息
会话记忆:每次会话时携带在上下文中的部分信息。用于让LLM回忆之前聊天内容。
需要注意的是,在SpringAI中是没有会话历史(ChatHistory)的,只有会话记忆(ChatMemory)。
会话记忆是会话历史的一部分,存在以下问题:
默认只保留最近20条消息,旧消息会被清除
会话记忆中不保留推理模型的推理内容
如果想做到“完整聊天记录”,要自己设计数据库和业务接口,同时不能把ChatMemoryRepository当历史记录来用,因为它的职责只是给ChatMemory存消息。
ChatMemory:会话记忆,在其中管理会话记忆,但要改进实现,存储时不再只存20条,而是全部存储
ChatMemoryRepository:会话记忆的存储,我们可以存储到MySQL、MongoDB等任何地方,但是要改为增量存储,而不是覆盖旧消息。
2.1.会话记录管理
我们需要创建数据库表记录会话id等信息,并提供查询用户会话记录、删除记录等功能。
2.1.1.创建表
每次会话都有自己的唯一标识,也就是会话id(conversationId)。
会话不仅仅有id信息,在某些业务中,会话还会跟用户有关联,还跟业务有关联,所以要记录的信息就比较多:
chatId:会话id
title:标题
userId:本次会话关联的用户
type:业务类型,我们后续的案例有3个需要用到会话记忆,所以这里可以是:chat、service、pdf
chat:多模态聊天机器人
service:黑马智能客服
pdf:个人知识库chatPdf
createTime:会话创建时间
因此我们要创建一个来表示会话记录:
CREATE TABLE `spring_ai_chat_record` (
`id` VARCHAR(50) NOT NULL DEFAULT '' COMMENT '会话id' COLLATE 'utf8mb4_general_ci',
`title` VARCHAR(150) NULL DEFAULT '' COLLATE 'utf8mb4_general_ci',
`user_id` BIGINT UNSIGNED NOT NULL COMMENT '用户id',
`type` VARCHAR(50) NOT NULL DEFAULT '0' COMMENT 'chat:聊天机器人;service:智能客服;pdf:个人知识库' COLLATE 'utf8mb4_general_ci',
`create_time` TIMESTAMP NOT NULL DEFAULT (CURRENT_TIMESTAMP) COMMENT '会话创建时间',
PRIMARY KEY (`id`) USING BTREE,
INDEX `create_time` (`create_time`) USING BTREE
)
COMMENT='会话历史记录'
COLLATE='utf8mb4_general_ci'
ENGINE=InnoDB
;接着引入MyBatisPlus的依赖:
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-spring-boot3-starter</artifactId>
<version>3.5.10.1</version>
</dependency>2.1.2.创建实体类
@Data
@EqualsAndHashCode(callSuper = false)
@Accessors(chain = true) //返回自己,方便链式调用
@TableName("spring_ai_chat_record")
public class SpringAiChatRecord implements Serializable {
private static final long serialVersionUID = 1L;
/**
* 会话id
*/ @TableId(value = "id", type = IdType.INPUT)
private String id;
/**
* 会话标题
*/
private String title;
/**
* 用户id
*/ private Long userId;
/**
* chat:聊天机器人;service:智能客服;pdf:个人知识库
*/
private String type;
/**
* 会话创建时间
*/
private LocalDateTime createTime;
}2.1.3.编写mapper
public interface SpringAiChatRecordMappe extends BaseMapper<SpringAiChatRecord> {
@Select("SELECT id FROM spring_ai_chat_record WHERE type = #{type} and user_id = #{userId} ORDER BY create_time DESC")
List<String> findConversationIds(@Param("type") String type, @Param("userId") Long userId);
}2.1.4.编写service
@Service
public class SpringAiChatRecordServiceImpl extends ServiceImpl<SpringAiChatRecordMapper, SpringAiChatRecord> implements ISpringAiChatRecordService {
@Override
public void saveRecord(String type, String conversionId) {
//1.判断记录是否存在
Long count=this.lambdaQuery()
.eq(SpringAiChatRecord::getId,conversionId)
.count();
if(count!=null&&count>0){
//记录已存在,结束
return;
}
//2.保存记录
SpringAiChatRecord record=new SpringAiChatRecord();
record.setType(type);
record.setId(conversionId);
//TODO userId暂时写死,后续从sessionId获取
record.setUserId(1L);
//TODO 会话标题暂时用会话id,后续可以根据内容生成
record.setTitle(conversionId);
record.setCreateTime(LocalDateTime.now());
save(record);
}
@Override
public List<String> findConversationIds(String type) {
//TODO
return this.getBaseMapper().findConversationIds(type,1L);
}
}2.1.5.保存记录
修改ChatController中的逻辑,在对话时保存会话记录:
private final ChatClient chatClient;
private final ISpringAiChatRecordService recordService;
@RequestMapping(value = "/chat", produces = "text/html;charset=UTF-8")
public Flux<String> chat(@RequestParam(defaultValue = "讲个笑话") String prompt,
@RequestParam("chatId")String chatId) {
//保存会话记录
recordService.saveRecord("chat",chatId);
return chatClient
.prompt(prompt)
.advisors(as->as.param(ChatMemory.CONVERSATION_ID,chatId))
.stream()
.chatResponse()
.flatMap(response->{
String thinking = response.getResult().getMetadata().get("thinking");
String answer = response.getResult().getOutput().getText();
if (thinking != null && !thinking.isBlank()) {
return Flux.just("\n" + thinking);
}
if (answer != null && !answer.isBlank()) {
return Flux.just(answer);
}
return Flux.empty();
});
}2.2.会话历史
会话历史的查询。包含两个接口:
根据业务类型查询会话历史列表(我们将来有3个不同业务,需要分别记录历史。大家的业务可能是按userId记录,根据UserId查询)
根据chatId查询指定会话的历史消息
2.2.1.消息VO
其中,查询会话历史消息,也就是Message集合。但是由于Message并不符合页面的需要,我们需要自己定义一个VO.
定义一个com.itheima.ai.entity.vo包,在其中定义一个MessageVO类:
@NoArgsConstructor
@Data
public class MessageVO {
private String role;
private String content;
public MessageVO(Message message){
switch (message.getMessageType()){
case USER:
role="user";
break;
case ASSISTANT:
role="assistant";
break;
default:
role="";
break;
}
this.content=message.getText();
}
}2.2.2.会话历史接口
新建一个ChatHistoryController:
@RestController
@RequestMapping("/ai/history")
@RequiredArgsConstructor
public class ChatHistoryController {
private final ChatHistoryRepository chatHistoryRepository;
private final ISpringAiChatRecordService recordService;
private final ChatMemoryRepository chatMemoryRepository;
@GetMapping("/{type}")
public List<String> getChatIds(@PathVariable("type") String type){
return recordService.findConversationIds(type);
}
@GetMapping("/{type}/{chatId}")
public List<MessageVO> getChatHistory(@PathVariable("type")String type,@PathVariable("chatId")String chatId){
return chatMemoryRepository.findByConversationId(chatId).stream().map(MessageVO::new).toList();
}
}重启服务,现在AI聊天机器人就具备会话记忆和会话历史功能了。